ELMo(三):Illustrated
2021/09/01
-----

https://pixabay.com/zh/photos/beard-the-old-man-turban-india-2268096/
-----

# Outline
-----
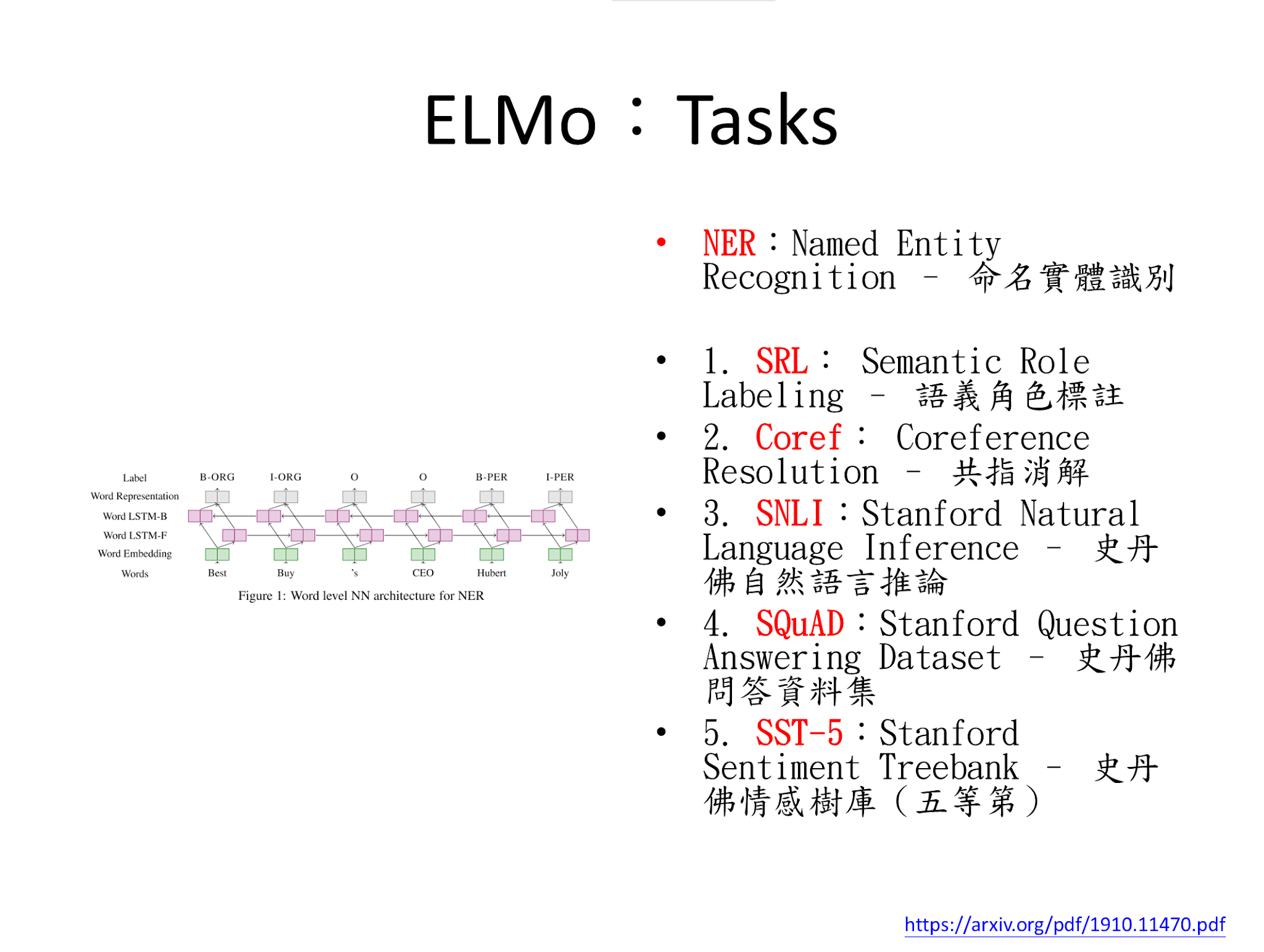
# Tasks
-----

說明:
POS、CHUNK、NER、SRL,都可使用 Word Embedding 後,以 LSTM 進行 Supervised 的訓練,來完成。
--
BIO 與 BIOES。
「B,即 Begin,表示開始。I,即 Intermediate,表示中間。E,即 End,表示結尾。S,即Single,表示單個字符。O,即 Other,表示其他,用於標記無關字符。」
「將“小明在北京大學的燕園看了中國男籃的一場比賽”這句話,進行標註,結果就是:
[B-PER,E-PER,O, B-ORG,I-ORG,I-ORG,E-ORG,O,B-LOC,E-LOC,O,O,B-ORG,I-ORG,I-ORG,E-ORG,O,O,O,O]」
https://zhuanlan.zhihu.com/p/88544122
-----
SRL

-----
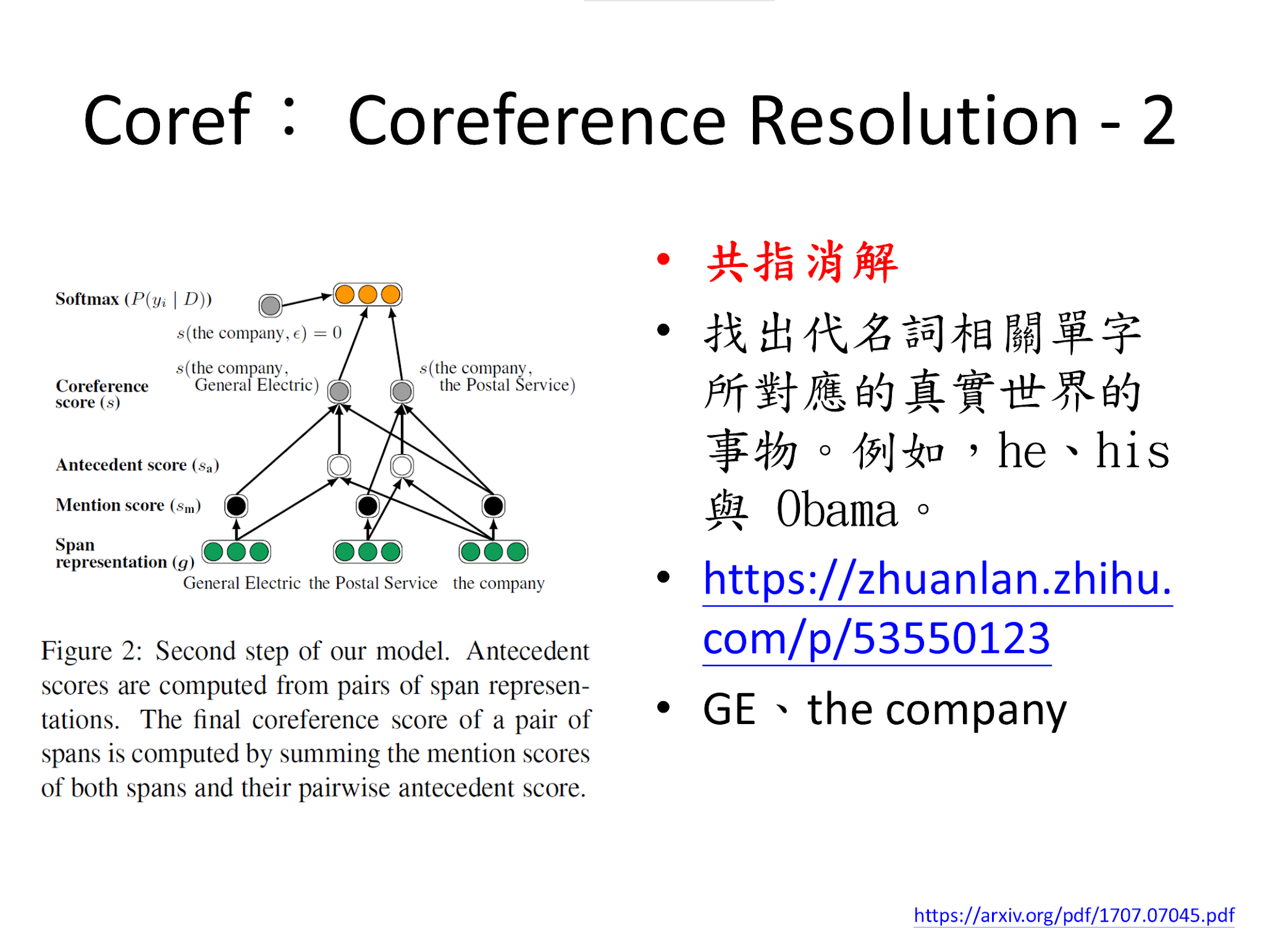
Coref

--
--
共指消解(Coreference Resolution or Reference Resolution)
找出代名詞相關單字所對應的真實世界的事物。例如,he、his 與 Obama。
https://zhuanlan.zhihu.com/p/53550123
-----
SNLI

Stanford Natural Language Inference
entailment:蘊含、推理。
contradiction:矛盾、對立。
neutral:中立、無關。
https://blog.eson.org/pub/a1c27ad7/
-----
SQuAD

https://zhuanlan.zhihu.com/p/137828922
-----
SST-5

--
「The Stanford Sentiment Treebank is a corpus with fully labeled parse trees that allows for a complete analysis of the compositional effects of sentiment in language. The corpus is based on the dataset introduced by Pang and Lee (2005) and consists of 11,855 single sentences extracted from movie reviews. It was parsed with the Stanford parser and includes a total of 215,154 unique phrases from those parse trees, each annotated by 3 human judges.」
斯坦福情感樹庫是一個帶有完全標記的解析樹的語料庫,可以對語言中情感的構成效應進行完整的分析。該語料庫基於 Pang 和 Lee (2005) 引入的數據集,包含從電影評論中提取的 11,855 個單句。它使用斯坦福解析器進行解析,包括來自這些解析樹的總共 215,154 個獨特的短語,每個短語由3 位人類判斷進行註釋。
「Each phrase is labelled as either negative, somewhat negative, neutral, somewhat positive or positive. The corpus with all 5 labels is referred to as SST-5 or SST fine-grained. Binary classification experiments on full sentences (negative or somewhat negative vs somewhat positive or positive with neutral sentences discarded) refer to the dataset as SST-2 or SST binary.」
每個短語都被標記為消極、有點消極、中性、有點積極或積極。具有所有 5 個標籤的語料庫被稱為 SST-5 或 SST 細粒度。完整句子的二元分類實驗(否定或有點否定 vs 有點肯定或肯定,丟棄中性句子)將數據集稱為 SST-2 或 SST 二進制。
https://paperswithcode.com/dataset/sst
https://blog.csdn.net/xxr233/article/details/115456578
-----

--

Modified from # BERT。
說明:
預訓練可以輸出三層的上下文向量。
-----

-----

Figure 2: Visualization of softmax normalized biLM layer weights across tasks and ELMo locations. Normalized weights less then 1/3 are hatched with horizontal lines and those greater then 2/3 are speckled.
圖 2:跨任務和 ELMo 位置的 softmax 歸一化 biLM 層權重的可視化。 小於 1/3 的歸一化權重用水平線陰影,大於 2/3 的那些有斑點。
# ELMo
說明:
「Visualization of learned weights
Figure 2 visualizes the softmax-normalized learned layer weights. At the input layer, the task model favors the first biLSTM layer. For coreference and SQuAD, the this is strongly favored, but the distribution is less peaked for the other tasks. The output layer weights are relatively balanced, with a slight preference for the lower layers.」
學習權重的可視化
圖 2 可視化了經過 softmax 歸一化的學習層權重。 在輸入層,任務模型偏向於第一個 biLSTM 層。 對於共指和 SQuAD,這是非常受歡迎的,但其他任務的分佈不那麼高。 輸出層權重相對均衡,對較低層略有偏愛。
https://www.groundai.com/project/deep-contextualized-word-representations/1
-----

--

說明:
「對於 GloVe ,多義詞比如 play,根據它的 embedding 找出的最接近的其它單詞大多數集中在體育,這很明顯是因為訓練數據中包含 play 句子中體育領域的數量明顯較多。」
「使用 ELMo,根據上下文動態調整後的 embedding 不僅能夠找出對應的「演出」的相同語義的句子,而且還可以保證找出的句子中的 play 對應的詞性也是相同的。之所以會這樣,是因為,第一層 LSTM 編碼了很多句法信息。」
https://blog.csdn.net/qq_35883464/article/details/100173045
-----
References
# ELMo。被引用 5229 次。ELMo 是 Context2vec 中,做的最好的。
Peters, Matthew E., et al. "Deep contextualized word representations." arXiv preprint arXiv:1802.05365 (2018).
https://arxiv.org/pdf/1802.05365.pdf
# BERT。被引用 12556 次。
Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
https://arxiv.org/pdf/1810.04805.pdf
# NER
Yadav, Vikas, and Steven Bethard. "A survey on recent advances in named entity recognition from deep learning models." arXiv preprint arXiv:1910.11470 (2019).
https://arxiv.org/pdf/1910.11470.pdf
# SRL
Tan, Zhixing, et al. "Deep semantic role labeling with self-attention." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.
https://ojs.aaai.org/index.php/AAAI/article/download/11928/11787
# Coref
Lee, Kenton, et al. "End-to-end neural coreference resolution." arXiv preprint arXiv:1707.07045 (2017).
https://arxiv.org/pdf/1707.07045.pdf
# SNLI
Camburu, Oana-Maria, et al. "e-snli: Natural language inference with natural language explanations." arXiv preprint arXiv:1812.01193 (2018).
https://arxiv.org/pdf/1812.01193.pdf
# SQuAD
Rajpurkar, Pranav, Robin Jia, and Percy Liang. "Know what you don't know: Unanswerable questions for SQuAD." arXiv preprint arXiv:1806.03822 (2018).
https://arxiv.org/pdf/1806.03822.pdf
-----
The Star Also Rises: ELMo
https://hemingwang.blogspot.com/2019/04/elmo.html
-----

No comments:
Post a Comment