FCN(三):Illustrated
2021/04/08
-----
https://pixabay.com/zh/vectors/network-iot-internet-of-things-782707/
-----
# ICNet
說明:
ICNet 在速度與正確性兩者間取得平衡。
-----
Figure 1. Fully convolutional networks can efficiently learn to make dense predictions for per-pixel tasks like semantic segmentation.
圖1. 全卷積網路可以有效地學習為每個像素任務(如語義分割)做出密集的預測。
# FCN
說明:
將最後一層熱圖經由 deconvolution 放大到原圖大小。實際上是 20 類加上背景 1 類。
最後 21 張熱圖,先透過 deconvolution 放大到原圖大小,然後 21 張的每個 xij 的點,最大值的點為預測類別。跟 groundtruth 比較後,可以知道預測是對還是不對。假設預測對的機率是 p,則使用 cross entropy loss(或其他)作為損失函數即可。
以此圖為例,訓練時 21 張特徵圖,有三張特徵圖,用貓狗背景當標籤。
-----
Figure 2. Transforming fully connected layers into convolution layers enables a classification net to output a heatmap. Adding layers and a spatial loss (as in Figure 1) produces an efficient machine for end-to-end dense learning.
圖2. 將全連接層轉換為卷積層使分類網能夠輸出熱圖。 增加層數和空間損失(如圖1 所示)將為端到端的密集學習提供一種高效的機器。
# FCN
說明:
將全連接層改成卷積層,則輸入不再需要固定大小。
以此圖為例,每張圖預測 1000 種類別,變成每個點預測 1000 種類別。同類別的點,集中成一張特徵圖。
如何決定一個點 xij 的類別?所有類別的特徵圖的 xij,最大值那張特徵圖的類別,即是 xij 預測的類別。
-----
# Focal Loss
說明:
Cross Entropy Loss,只要計算正確點的機率 p,的 - log( p ),即可。我們希望 p 越大越好,最好接近 1。p 越大,- log( p ) 越小(還是正值)。p = 1 時,Loss 為 0。
參考資料一
−(ylog(p)+(1−y)log(1−p))
Loss Functions — ML Glossary documentation
https://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html
參考資料二
損失函數|交叉熵損失函數- 知乎
https://zhuanlan.zhihu.com/p/35709485
參考資料三
https://blog.csdn.net/u014380165/article/details/77284921
參考資料四
https://eli.thegreenplace.net/2016/the-softmax-function-and-its-derivative/
-----
Figure 4.1: The transpose of convolving a 3 x �3 kernel over a 4 x �4 input using unit strides (i.e., i = 4, k = 3, s = 1 and p = 0). It is equivalent to convolving a 3� x 3 kernel over a 2� x 2 input padded with a 2� x 2 border of zeros using unit strides (i.e., i0 = 2, k0 = k, s0 = 1 and p0 = 2).
圖4.1:使用步幅將 3 x 3 內核卷積在 4 x 4 輸入上的轉置(即,i = 4,k = 3,s = 1 和 p = 0)。 這等效於使用單位步長(即 i0 = 2,k0 = k,s0 = 1 和 p0 = 2)在 2 x 2 輸入填充的 2 x 2 輸入上卷積 3 x 3 內核,並用零的 2 x 2 邊界填充。
# A Guide
說明:
先做 0 padding,然後用 3 x 3 的卷積核將 2 x 2 的圖放大到 4 x 4。
-----
Figure 3. Our DAG nets learn to combine coarse, high layer information with fine, low layer information. Pooling and prediction layers are shown as grids that reveal relative spatial coarseness, while intermediate layers are shown as vertical lines. First row (FCN-32s): Our singlestream net, described in Section 4.1, upsamples stride 32 predictions back to pixels in a single step. Second row (FCN-16s): Combining predictions from both the final layer and the pool4 layer, at stride 16, lets our net predict finer details, while retaining high-level semantic information. Third row (FCN-8s): Additional predictions from pool3, at stride 8, provide further precision.
圖3. 我們的 DAG 網路學習將粗糙的高層信息與精細的低層信息相結合。 池化層和預測層顯示為顯示相對空間粗糙度的網格,而中間層顯示為垂直線。 第一行(FCN-32s):如第 4.1 節所述,我們的單資料流網路將一步一步將步幅 32 的預測向上擴展至像素。 第二行(FCN-16):在步幅 16 結合來自最後一層和 pool4 層的預測,使我們的網路可以預測更精細的細節,同時保留高級語義信息。 第三行(FCN-8s):在步幅 8 中,來自 pool3 的其他預測提供了更高的精度。
說明:
FCN-32s 是將最後一層 deconv 32 倍。
FCN-16s 是將最後一層 deconv 2 倍,點對點相加,再 deconv 16 倍。較大的特徵圖要先預測,取出 21 張。
FCN-8s 是將最後一層 deconv 4 倍,點對點相加,再 deconv 8 倍。較大的特徵圖要先預測,取出 21 張。
-----
Table 1. We adapt and extend three classification convnets. We compare performance by mean intersection over union on the validation set of PASCAL VOC 2011 and by inference time (averaged over 20 trials for a 500 x� 500 input on an NVIDIA Tesla K40c). We detail the architecture of the adapted nets with regard to dense prediction: number of parameter layers, receptive field size of output units, and the coarsest stride within the net. (These numbers give the best performance obtained at a fixed learning rate, not best performance possible.)
表1. 我們適應並擴展了三個分類卷積。 我們通過PASCAL VOC 2011 驗證集上的平均交集與並集以及推理時間(在 NVIDIA Tesla K40c 上進行 500 x 500 輸入的 20 多次試驗中得出的平均值)來比較性能。 我們針對密集預測詳細介紹了自適應網路的架構:參數層數,輸出單元的感受野大小以及網路內最粗的步幅。 (這些數字給出了以固定學習率獲得的最佳性能,而不是最佳性能。)
說明:
VGG16 效果最好。為何比 GoogLeNet 好?
rf size reception filter size
https://stackoverflow.com/questions/35582521/how-to-calculate-receptive-field-size
-----
Figure 4. Refining fully convolutional nets by fusing information from layers with different strides improves segmentation detail. The first three images show the output from our 32, 16, and 8 pixel stride nets (see Figure 3).
圖4. 通過融合來自具有不同跨度的圖層的信息來完善全卷積網路,可以改善分割細節。 前三個圖像顯示了我們 32、16 和 8 像素步幅網路的輸出(請參見圖3)。
說明:
FCN-32s 直接放大 32 倍。糊掉了。
-----
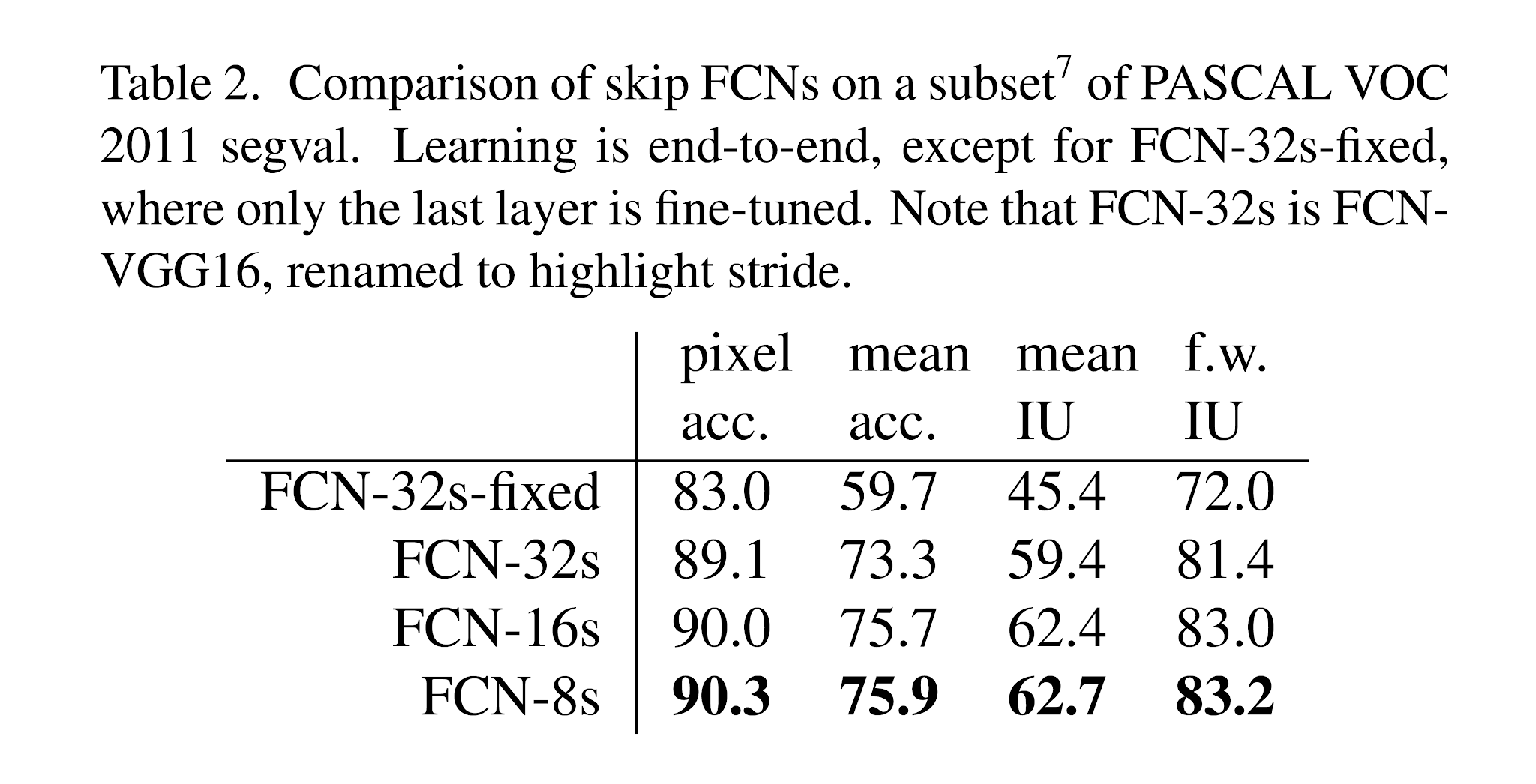
Table 2. Comparison of skip FCNs on a subset7 of PASCAL VOC 2011 segval. Learning is end-to-end, except for FCN-32s-fixed, where only the last layer is fine-tuned. Note that FCN-32s is FCN-VGG16, renamed to highlight stride.
表2. PASCAL VOC 2011 segval 的 subset7 上的跳過 FCN 的比較。 學習是端到端的,除了 FCN-32s 固定的(僅對最後一層進行微調)之外。 請注意,FCN-32 是 FCN-VGG16,已重命名以突出顯示步幅。
說明:
pixel accuracy 像素的正確率。
mean accuracy 類別準確率的平均。
mean IU(mIOU),IoU = TP / (TP + FP + FN)。 每類先算 IOU 再平均。
frequency weighted IU。根據每個類別出現的頻率設置權重。
https://medium.com/@chingi071/fully-convolutional-networks-%E8%AB%96%E6%96%87%E9%96%B1%E8%AE%80-246aa68ce4ad
-----
Figure 5. Training on whole images is just as effective as sampling patches, but results in faster (wall time) convergence by making more efficient use of data. Left shows the effect of sampling on convergence rate for a fixed expected batch size, while right plots the same by relative wall time.
圖5. 對整個圖像進行訓練與採樣色塊一樣有效,但是通過更有效地利用資料可以加快(牆上時間)收斂。 左圖顯示了對於固定的預期批次大小,採樣對收斂速度的影響,而右圖則通過相對牆上時間繪製了相同的結果。
說明:
取樣對批次次數無影響,但不取樣收斂時間較短,因為沒有重複的資料,比較有效率。
「wall time。這個很好理解,它就是我們從計算開始到計算結束等待的時間。除此之外,CPU time 也是一個常見的時間數據。CPU time 衡量的是 CPU 用來執行程序的時間。當軟件使用一個線程時,由於需要等待 IO 完成或者用戶輸入等原因,CPU 並不總是 100% 被使用,這導致CPU time 一般比 wall time 小。」
https://zhuanlan.zhihu.com/p/39891521
「如果 patchwise 的一個批處理剛好包含了價值函數所對整張圖接受,則相當於輸入整張圖像。但 patchwise 的方法卻每次每取一次批處理,總會有一些圖像塊是有重疊的。 輸入整張圖卻可以避免 patchbatch 之間的重疊,這樣更加高效。」。
https://www.daimajiaoliu.com/daima/6108d2427c9c805
-----
Table 3. Our fully convolutional net gives a 20% relative improvement over the state-of-the-art on the PASCAL VOC 2011 and 2012 test sets and reduces inference time.
表3. 我們的全卷積網路相對於 PASCAL VOC 2011 和 2012 測試集的最新技術提供了 20% 的相對改進,並減少了推理時間。
說明:
比 SDS 與 R-CNN 好。
-----
Figure 6. Fully convolutional segmentation nets produce stateof-the-art performance on PASCAL. The left column shows the output of our highest performing net, FCN-8s. The second shows the segmentations produced by the previous state-of-the-art system by Hariharan et al. [15]. Notice the fine structures recovered (first row), ability to separate closely interacting objects (second row), and robustness to occluders (third row). The fourth row shows a failure case: the net sees lifejackets in a boat as people.
圖6. 全卷積分割網在 PASCAL 上表現出最先進的性能。 左列顯示了性能最高的網路 FCN-8 的輸出。 第二部分顯示了 Hariharan 等人先前的最新系統所產生的分割結果,[15]。 注意恢復的精細結構(第一列),分離緊密相互作用的對象的能力(第二列)以及對遮擋物的穩健性(第三列)。 第四列顯示了一個失敗案例:網路將船上的救生衣視為人。
說明:
第一列,精細結構。
第二列,分離緊密的能力。
第三列,遮擋物。
救生衣認成人是 FCN 的缺點。SDS 為何不會?
-----
Fig. 1. U-net architecture (example for 32x32 pixels in the lowest resolution). Each blue box corresponds to a multi-channel feature map. The number of channels is denoted on top of the box. The x-y-size is provided at the lower left edge of the box. White boxes represent copied feature maps. The arrows denote the different operations.
圖1. U-net架構(最低分辨率的 32x32 像素範例)。 每個藍色框對應一個多通道特徵圖。 通道數顯示在框的頂部。 x-y 尺寸位於框的左下邊緣。 白框代表複製的特徵圖。 箭頭表示不同的操作。
說明:
黑色往右的箭頭。Conv3、ReLU。
灰色往右的箭頭。拷貝與裁減。
磚色往下的箭頭。max pooling 2 x 2。
綠色往上的箭頭。Deconv 2 x 2。
藍色往右的箭頭。Conv1。
虛線。裁減。
白框代表複製的特徵圖。
最後特徵圖為何有兩張?由於該任務是一個二分類任務,所以網路有兩個輸出 Feature Maps(背景與物件)。
損失函數此處不討論,可參考下方文章。
https://zhuanlan.zhihu.com/p/43927696
-----
Fig. 1.We improve DeepLabv3, which employs the spatial pyramid pooling module (a), with the encoder-decoder structure (b). The proposed model, DeepLabv3+, contains rich semantic information from the encoder module, while the detailed object boundaries are recovered by the simple yet effective decoder module. The encoder module allows us to extract features at an arbitrary resolution by applying atrous convolution.
圖1. 我們改進了 DeepLabv3,它使用了空間金字塔池模塊(a)和編碼器-解碼器結構(b)。 提出的模型 DeepLabv3 + 包含來自編碼器模塊的豐富語義信息,而詳細的對象邊界由簡單而有效的解碼器模塊恢復。 編碼器模塊允許我們通過應用空洞卷積以固定分辨率提取特徵。
說明:
spatial pyramid pooling 的部分為示意圖,細節可以參考圖 2。
-----
Fig. 2. Our proposed DeepLabv3+ extends DeepLabv3 by employing a encoderdecoder structure. The encoder module encodes multi-scale contextual information by applying atrous convolution at multiple scales, while the simple yet effective decoder module refines the segmentation results along object boundaries.
圖2。我們提出的 DeepLabv3 +通過採用編碼器/解碼器結構擴展了 DeepLabv3。 編碼器模塊通過在多個尺度上應用空洞卷積來編碼多尺度上下文資訊,而簡單而有效的解碼器模塊則沿著對象邊界細化分段結果。
說明:
Encoder 架構跟 Inception 類似。
-----
Fig. 3. 3×3 Depthwise separable convolution decomposes a standard convolution into (a) a depthwise convolution (applying a single filter for each input channel) and (b) a pointwise convolution (combining the outputs from depthwise convolution across channels). In this work, we explore atrous separable convolution where atrous convolution is adopted in the depthwise convolution, as shown in (c) with rate = 2.
圖3。3×3 深度可分離卷積將標準卷積分解為(a)深度卷積(對每個輸入通道應用單個濾波器)和(b)點向卷積(合併跨通道的深度卷積的輸出)。 在這項工作中,我們探索了空洞可分離卷積,其中在深度卷積中採用了空洞卷積,如(c)中所示,速率為 2。
說明:
a:一般卷積。
b:Conv1。
c:空洞卷積。或擴張卷積。
-----
# FCN
Long, Jonathan, Evan Shelhamer, and Trevor Darrell. "Fully convolutional networks for semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf
# Guide to convolution
Dumoulin, Vincent, and Francesco Visin. "A guide to convolution arithmetic for deep learning." arXiv preprint arXiv:1603.07285 (2016).
https://arxiv.org/pdf/1603.07285.pdf
# RetinaNet(Focal Loss)
Lin, Tsung-Yi, et al. "Focal loss for dense object detection." IEEE transactions on pattern analysis and machine intelligence (2018).
https://vision.cornell.edu/se3/wp-content/uploads/2017/09/focal_loss.pdf
# U-Net
Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015.
https://arxiv.org/pdf/1505.04597.pdf
# DeepLab v3+
Chen, Liang-Chieh, et al. "Encoder-decoder with atrous separable convolution for semantic image segmentation." Proceedings of the European conference on computer vision (ECCV). 2018.
http://openaccess.thecvf.com/content_ECCV_2018/papers/Liang-Chieh_Chen_Encoder-Decoder_with_Atrous_ECCV_2018_paper.pdf
Multi-class cross entropy loss
https://www.oreilly.com/library/view/hands-on-convolutional-neural/9781789130331/7f34b72e-f571-49d2-a37a-4ed6f8011c93.xhtml
Review: FCN — Fully Convolutional Network (Semantic Segmentation) | by Sik-Ho Tsang | Towards Data Science
https://towardsdatascience.com/review-fcn-semantic-segmentation-eb8c9b50d2d1
FCN 的简单实现 - 知乎
https://zhuanlan.zhihu.com/p/32506912
FCN的学习及理解(Fully Convolutional Networks for Semantic Segmentation)_凹酱的DEEP LEARNING-CSDN博客_fcn
https://blog.csdn.net/qq_36269513/article/details/80420363
Fully Convolutional Networks 論文閱讀 | by 李謦伊 | May, 2021 | Medium
https://medium.com/@chingi071/fully-convolutional-networks-%E8%AB%96%E6%96%87%E9%96%B1%E8%AE%80-246aa68ce4ad
图像分割的U-Net系列方法 - 知乎
https://zhuanlan.zhihu.com/p/57530767
【U-Net】语义分割之U-Net详解 - 咖啡味儿的咖啡 - CSDN博客
https://blog.csdn.net/wangdongwei0/article/details/82393275
深入理解深度学习分割网络Unet——U-Net Convolutional Networks for Biomedical Image Segmentation - 未来不再遥远 - CSDN博客
https://blog.csdn.net/Formlsl/article/details/80373200
-----
以下只列出論文
-----
# V-Net
Milletari, Fausto, Nassir Navab, and Seyed-Ahmad Ahmadi. "V-net: Fully convolutional neural networks for volumetric medical image segmentation." 2016 fourth international conference on 3D vision (3DV). IEEE, 2016.
https://arxiv.org/pdf/1606.04797.pdf
# 3D U-Net
Çiçek, Özgün, et al. "3D U-Net: learning dense volumetric segmentation from sparse annotation." International conference on medical image computing and computer-assisted intervention. Springer, Cham, 2016.
https://arxiv.org/pdf/1606.06650.pdf
# Deep Learning in Medical Image
Litjens, Geert, et al. "A survey on deep learning in medical image analysis." Medical image analysis 42 (2017): 60-88.
https://arxiv.org/pdf/1702.05747.pdf
# Skip Connections in Biomedical Image Segmentation
Drozdzal, Michal, et al. "The importance of skip connections in biomedical image segmentation." Deep Learning and Data Labeling for Medical Applications. Springer, Cham, 2016. 179-187.
https://arxiv.org/pdf/1608.04117.pdf
# Attention U-Net
Oktay, Ozan, et al. "Attention u-net: Learning where to look for the pancreas." arXiv preprint arXiv:1804.03999 (2018).
https://arxiv.org/pdf/1804.03999.pdf
# U-Net++
Zhou, Zongwei, et al. "Unet++: A nested u-net architecture for medical image segmentation." Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. Springer, Cham, 2018. 3-11.
https://arxiv.org/pdf/1807.10165.pdf
MultiResUNet
Ibtehaz, Nabil, and M. Sohel Rahman. "MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation." Neural Networks 121 (2020): 74-87.
https://arxiv.org/pdf/1902.04049.pdf
DC-UNet
Lou, Ange, Shuyue Guan, and Murray Loew. "DC-UNet: Rethinking the U-Net Architecture with Dual Channel Efficient CNN for Medical Images Segmentation." arXiv preprint arXiv:2006.00414 (2020).
https://arxiv.org/ftp/arxiv/papers/2006/2006.00414.pdf
-----