NLP(五):Transformer
2019/01/17
2020/12/15
前言:
前言:
Transformer,以及由雙向 Transformer Encoder 構成的預訓練模型 BERT,可說是現代 NLP 的起點。Transformer 同時也用到 兩篇 CV 的論文,NIN 的 Conv1 來升降維,以及 ResNet 的 identity mapping(由早期 NLP 的主要元件 LSTM 的直通架構得到靈感)。而 Transformer 的 self attention 也被 CV 拿回去使用。可以說,當代深度學習,CV 與 NLP 是不斷交互影響的。
在十篇經典的深度學習論文(LeNet、NIN、ResNet、FCN、YOLO、LSTM、Seq2seq、Attention、ConvS2S、Transformer)裡:
LeNet 主要體現了一個完整的 CNN,NIN 提供了 Conv1 作為深度學習的必備元件,ResNet 提供了 identity mapping 作為深度學習的必備元件。FCN 與 YOLO 則為 CNN 在 CV 的主要應用。可以說 LeNet、NIN、ResNet 這一棵 Image Classification 的大樹,長出了 Semantic Segmentation 與 Object Detection 兩條主幹。
另一方面,從 LSTM 這個基本元件,套用 Encoder-Decoder 的架構,產生了 Seq2seq。由單一 Context 向量細部化,透過多 Context 向量,於是有了 Attention。由 RNN 轉向 一維 CNN 的 ConvS2S,除了可以使用 GPU 平行運算的功能,最主要的成果還有導入 QKV,讓詞向量的分解更細緻。ConvS2S 的 QKV 作用於 Encoder 與 Decoder 之間,Transformer 的 QKV 則是分別先在 Encoder 與 Decoder 先進行。然後從 Encoder 的最後一層的 KV 與 Decoder 每一層的 Q 連起來。 使得 QKV 又更細緻了。Seq2seq、Attention、ConvS2S、Transformer,我把它們命名為 Source Target Output Relational Model,簡稱 STORM。
前年年底,我自學了三個月的 NLP,知道 NLP 五篇經典論文,由於在網路上遇到博士班的口試委員,因為被稱讚文章寫的不錯,於是自告奮勇到他們實驗室報告,NLP 五篇之外,也選了 CV 五篇。Transformer 就是為了報告,強迫自己讀懂得。後來報告時間不夠,還找了地方跟 PyTorch Taichung 的社長一個人講完。ResNet 被問倒了。後來年底實驗了三個月共十次的收費論文研討,共三十小時,除了 ResNet v1 與 v2,另外讀了 Dropout、Essemble、與 Visualization 的版本,總算對 ResNet 有了基本的掌握。
2019 年底的收費論文研討大約有十位參加者,我讓所有參加者免費聽 2020 的全方位 AI 課程,並且邀請其中五位,每人報告兩次,含我自己十次,一共二十次,共六十小時。新的參加者大約也是十人。定價由三萬調整到五萬,實際收費則是由一萬五千左右調整為四萬左右。收入遠不到需要報稅的水準,但是可以有很多時間讀論文。
從社團論文研討到收費論文研討再到全方位 AI 課程,其實核心都是希望深度學習者可以自己報告論文,而不是聽別人報告論文,這個觀念並不是很能被理解或接受。我自己,則是透過不斷地寫論文導讀,與進行論文報告,而持續進步。
Transformer 上次報告,只理解表面與大意。經過一年的持續學習,除了報告 Word2vec 以及 Short Attention 的 QKV 之外,ConvS2S 也更深入理解了,對於理解 Transformer 的架構幫助很大。細節上,則搞清楚 Positional Embedding。
這篇前言寫的有點長,算是為
丁酉:從 LeNet 到 LeNet 實作團到 DRL 實作團到 PyTorch Taiwan。
戊戌:從 PyTorch Taipei 開始,主要報告 CV。年底開始自學 NLP。
己亥:策劃十篇經典論文,給 PyTorch New Taipei 作為報告主題。年底進行收費論文研討。
庚子:全方位 AI 課程。
這四年的深度學習,進行一個簡單的回顧。

Transformer 可以跟 ConvS2S 一起讀,比較其中的異同。
相同的部分,都是 Encoder-Decoder 的架構。一開始都是 Word Embedding 與 Positional Embedding。都有用到 QKV 的觀念。Encoder 的最後一層,作為 Decoder 每一層的輸入。Decoder 每一層的輸出,作為 Decoder 下一層的輸入。Decoder 的最後一層,每次輸出一個字。
相異的部分,Transformer 的 Encoder,每一層會有一個 Multi-Head 的 self attention。另外 Decoder 的每一層,除了與 Encoder 連在一起的 Multi-Head attention,還先做了 Masked Multi-Head self attention。
-----
圖二、Outline。
-----
Outline
1.1. Transformer
1.2. I/O Embedding
1.3. Positional Encoding
2.1. Attention
2.2. Multi-Head
2.3. Multi-Layer
2.4. Skip Connection
2.5. Layer Normalization
2.6. FNN
3.1. Masked
3.2. Linear and Softmax
3.3. Prediction
4.1. QKV
4.2. Softmax and Root of dk
-----
1. Transformer
2. I/O Embedding
Word2Vec。
3. Positional Encoding
公式跟跟訓練結果差不多,用公式。
4. Attention
Query、Key、Value。
5. Multi-Head
多個卷積核。
6. Skip Connection
ResNet(Dropout)。
7. Layer Normalization
BN 每筆資料每層的某個位置正規化
LN 某筆資料某層的所有位置正規化
正規化 - 減 mean 再除以 STD
8. FFN
調整輸出跟輸入的維度
9. Masked
保持 Auto Regression,output 不考慮 i 之後字的因素。
10. Linear and Softmax
打分數
下面三個是 attention 公式:
11. Softmax
Logistic Regression 的推廣
資料為 0 ~ 1 之間,總和為 1 的離散機率分布
12. QKV
QK 對齊(內積、餘弦相似)。(如果 FNN 的話,是加法)。
13. Root of dk
dk:dimension of K,避免向量的分量值透過 Logistic Regression 後都是 1 或者都是 0,造成無 attention。
-----
1.1. Transformer
-----

Fig. 1. Transformer [1]。
https://mchromiak.github.io/articles/2017/Sep/12/Transformer-Attention-is-all-you-need/#.X87jeOgzaUl
Outline
1.1. Transformer
1.2. I/O Embedding
1.3. Positional Encoding
2.1. Attention
2.2. Multi-Head
2.3. Multi-Layer
2.4. Skip Connection
2.5. Layer Normalization
2.6. FNN
3.1. Masked
3.2. Linear and Softmax
3.3. Prediction
4.1. QKV
4.2. Softmax and Root of dk
-----
1. Transformer
2. I/O Embedding
Word2Vec。
3. Positional Encoding
公式跟跟訓練結果差不多,用公式。
4. Attention
Query、Key、Value。
5. Multi-Head
多個卷積核。
6. Skip Connection
ResNet(Dropout)。
7. Layer Normalization
BN 每筆資料每層的某個位置正規化
LN 某筆資料某層的所有位置正規化
正規化 - 減 mean 再除以 STD
8. FFN
調整輸出跟輸入的維度
9. Masked
保持 Auto Regression,output 不考慮 i 之後字的因素。
10. Linear and Softmax
打分數
下面三個是 attention 公式:
11. Softmax
Logistic Regression 的推廣
資料為 0 ~ 1 之間,總和為 1 的離散機率分布
12. QKV
QK 對齊(內積、餘弦相似)。(如果 FNN 的話,是加法)。
13. Root of dk
dk:dimension of K,避免向量的分量值透過 Logistic Regression 後都是 1 或者都是 0,造成無 attention。
-----
1.1. Transformer
-----
Fig. 1. Transformer [1]。
https://mchromiak.github.io/articles/2017/Sep/12/Transformer-Attention-is-all-you-need/#.X87jeOgzaUl
圖三、Transformer。
左邊是 3 Stages 的 Encoder,右邊是 5 Stages 的 Decoder。右邊比左邊多的部分是 Stage 3 的連接層與 Stage 5 的輸出層。細節將在稍後的章節說明。
-----
1.2. I/O Embedding
-----
Weight Matrix of Word2vec

https://mc.ai/deep-nlp-word-vectors-with-word2vec/
圖四、1-hot Encoding to Vector。
1.3. Positional Encoding
-----

圖五、Positional Encoding。



-----
2.1. Attention
-----

-----
2.2. Multi-Head
-----


-----
2.3. Multi-Layer
-----


-----
2.4. Skip Connection
-----

-----
2.5. Layer Normalization
-----

// Papers With Code Positional Normalization
https://www.groundai.com/project/positional-normalization/1





https://medium.com/@joealato/attention-in-nlp-734c6fa9d983
圖三十、PKV。
從 Attention 到 Key-Value 到 QKV。
-----
-----
References
◎ 論文
-----
◎ 英文參考資料
# 綜述
Attention Attention!
https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time
https://jalammar.github.io/illustrated-transformer/
The Transformer – Attention is all you need. - Michał Chromiak's blog
https://mchromiak.github.io/articles/2017/Sep/12/Transformer-Attention-is-all-you-need/#.XEbkXPLxh1A
Paper Dissected 'Attention is All You Need' Explained _ Machine Learning Explained
http://mlexplained.com/2017/12/29/attention-is-all-you-need-explained/
Transformer Architecture Attention Is All You Need
https://medium.com/@adityathiruvengadam/transformer-architecture-attention-is-all-you-need-aeccd9f50d09
What is a Transformer – Inside Machine learning – Medium
https://medium.com/inside-machine-learning/what-is-a-transformer-d07dd1fbec04
Transformers – Towards Data Science
https://towardsdatascience.com/transformers-141e32e69591
9.3. Transformer — Dive into Deep Learning 0.7 documentation
https://d2l.ai/chapter_attention-mechanism/transformer.html
The Annotated Transformer
http://nlp.seas.harvard.edu/2018/04/03/attention.html
# skip connection
Understanding LSTM Networks -- colah's blog
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
# layer normalization
The Star Also Rises Normalization
https://hemingwang.blogspot.com/2019/10/normalization.html
# layer normalization
Weight Normalization and Layer Normalization Explained (Normalization in Deep Learning Part 2) _ Machine Learning Explained
https://mlexplained.com/2018/01/13/weight-normalization-and-layer-normalization-explained-normalization-in-deep-learning-part-2/
# softmax
Softmax - Hands-On Natural Language Processing with Python [Book]
https://www.oreilly.com/library/view/hands-on-natural-language/9781789139495/3550f443-190d-4931-8d57-29db02a3abff.xhtml
-----
◎ 日文參考資料
論文解説 Attention Is All You Need (Transformer) - ディープラーニングブログ
http://deeplearning.hatenablog.com/entry/transformer
# Masked
論文解説 Convolutional Sequence to Sequence Learning (ConvS2S) - ディープラーニングブログ
http://deeplearning.hatenablog.com/entry/convs2s
-----
◎ 簡體中文參考資料
一文读懂「Attention is All You Need」_ 附代码实现 _ 机器之心
https://www.jiqizhixin.com/articles/2018-01-10-20
tensor-to-tensor[理论篇] - daiwk-github博客
https://daiwk.github.io/posts/platform-tensor-to-tensor.html#422-attention
【NLP】Transformer详解 - 知乎
https://zhuanlan.zhihu.com/p/44121378
详解Transformer (Attention Is All You Need) - 知乎
https://zhuanlan.zhihu.com/p/48508221
-----
1.2. I/O Embedding
-----
Weight Matrix of Word2vec

https://mc.ai/deep-nlp-word-vectors-with-word2vec/
圖四、1-hot Encoding to Vector。
假定字彙數量是 10k,維度 10,000 的 one hot encoding 可以先經由 Word Embedding 壓縮成維度 300 的向量。
-----
1.3. Positional Encoding
-----

圖五、Positional Encoding。
公式 [1]。
pos:position。一個 word 在 sentence 中的位置。
i:dimension。Positional Embedding 向量的 index,最大值為 dmodel。
dmodel:Word Embedding 的維度。768、512,等等。
k:新增的位置向量的 offset。新增向量可由之前向量的線性組合構成,係數為 sin(k) 與 cos(k),參考圖六。
-----

圖六。
dpos 相當於圖五的 dmodel。
-----

圖七。
十個位置向量的編碼。交錯的版本。橫軸代表位置向量的分量,縱軸代表字在句中的位置。顏色代表數值。
-----
圖八。
廿個位置向量的編碼。未交錯的版本。橫軸代表位置向量的分量,縱軸代表字在句中的位置。顏色代表數值。
-----
圖九。
相加。
-----
2.1. Attention
-----

圖十、QKV。
第一層代表第一個字。
第二層代表第二個字。
2.2. Multi-Head
-----
圖十一、Multi Heads。
作者試出來多頭效果比較好,其作用類似 CNN 每層的多個特徵圖。
-----

-----


圖十二、QKV一。
QK 構成 Attention Table。
-----

圖十三、QKV二。
QKV一的實際運算。
-----

-----

-----

圖十四。
Layer 5 的八個多頭其中一個。
-----
圖十五。
Layer 5 的八個多頭其中兩個。
-----
圖十六。
Layer 5 的八個多頭。
-----

圖十七、Multi Heads。
先經過 self attention 再通過 FFN,作用與 Conv1 相同。
-----
2.3. Multi-Layer
-----
圖十八、Multi Layer。
六層 Decoder,每層的輸入都是 Encoder 的最後一層。
-----
圖十九、Decoder 的運算單元。
可以有多層,此處的例子為 6 層。
KV 來自 Encoder 的最後一層。Q 來自 Decoder 的前一層。
-----
2.4. Skip Connection
-----

圖二十、Carry。
ResNet 的 identity mapping 的靈感來源。
-----
2.5. Layer Normalization
-----

// Papers With Code Positional Normalization
https://www.groundai.com/project/positional-normalization/1
圖廿一、Normalization。
這張圖比 Group Normalization 論文裡面的圖清楚。
-----

// Weight Normalization and Layer Normalization Explained (Normalization in Deep Learning Part 2) _ Machine Learning Explained
-----

// Weight Normalization and Layer Normalization Explained (Normalization in Deep Learning Part 2) _ Machine Learning Explained
圖廿二、BN vs LN。
一個 Batch 裡面有好幾個 Layer。
-----
2.6. FFN
-----

Fig. 4.2. Conv1。
https://blog.csdn.net/zhangjunhit/article/details/55101559
-----
2.6. FFN
-----

Fig. 4.2. Conv1。
https://blog.csdn.net/zhangjunhit/article/details/55101559
圖廿三、Feed forward Network(FFN)。
每個輸出層的一個點,都由不同特徵圖的同一個位置的點,轉換得來。係數靠訓練。
-----
3.1. Masked
-----

-----
-----
3.1. Masked
-----

圖廿四、Masked。
未來的資訊,不可使用。
-----
1
2
3
4
-----
3.2. Linear and Softmax
-----

-----

-----
3.3. Prediction
-----
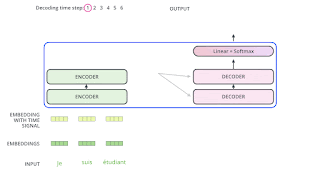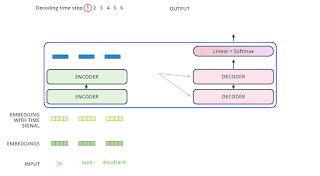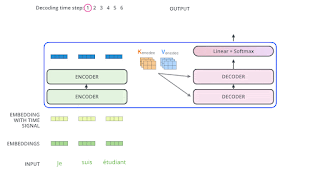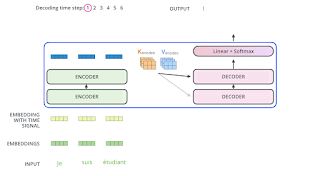
https://jalammar.github.io/illustrated-transformer/
3.2. Linear and Softmax
-----
圖廿五、輸出層。
先透過線性層決定要輸出哪個字,由數值轉為機率。然後輸出那個字。
-----

圖廿六、Softmax。
將數值轉為離散機率分布。
-----
3.3. Prediction
-----
圖廿七、預測下一個字。
一次輸出一個字。
-----
4.1. QKV
-----

-----
4.2. Softmax and Root of dk
-----

-----
-----
4.1. QKV
-----
圖廿八、QKV。
-----
4.2. Softmax and Root of dk
-----

圖廿九、Root of dk。
dk:dimension of K。k 為 QKV(三者的維度相同)的 K 的維度。除以一個值(往原點靠近),避免向量的分量值透過 Logistic Regression 後都是 1(正值太大) 或者都是 0(負值太小),造成無 attention。
-----

https://medium.com/@joealato/attention-in-nlp-734c6fa9d983
圖三十、PKV。
從 Attention 到 Key-Value 到 QKV。
-----
「Google 在論文中說到他們比較過直接訓練出來的位置向量和上述公式計算出來的位置向量,效果是接近的。因此顯然我們更樂意使用公式構造的 Position Embedding 了。」
-----
「缺點在原文中沒有提到,是後來在 Universal Transformers中指出的,在這裡加一下吧,主要是兩點: 實踐上:有些 rnn 輕易可以解決的問題 transformer 沒做到,比如復制 string,尤其是碰到比訓練時的 sequence 更長的時理論上:transformers 非 computationally universal(圖靈完備),(我認為)因為無法實現 “while” 循環 4. 總結 Transformer 是第一個用純 attention 搭建的模型,不僅計算速度更快,在翻譯任務上也獲得了更好的結果。Google 現在的翻譯應該是在此基礎上做的,但是請教了一兩個朋友,得到的答案是主要看數據量,數據量大可能用 transformer 好一些,小的話還是繼續用 rnn-based model」。
-----
References
◎ 論文
[1] Transformer
Vaswani, Ashish, et al. "Attention is all you need." Advances in Neural Information Processing Systems. 2017.
https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf -----
◎ 英文參考資料
# 綜述
Attention Attention!
https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time
https://jalammar.github.io/illustrated-transformer/
The Transformer – Attention is all you need. - Michał Chromiak's blog
https://mchromiak.github.io/articles/2017/Sep/12/Transformer-Attention-is-all-you-need/#.XEbkXPLxh1A
Paper Dissected 'Attention is All You Need' Explained _ Machine Learning Explained
http://mlexplained.com/2017/12/29/attention-is-all-you-need-explained/
Transformer Architecture Attention Is All You Need
https://medium.com/@adityathiruvengadam/transformer-architecture-attention-is-all-you-need-aeccd9f50d09
What is a Transformer – Inside Machine learning – Medium
https://medium.com/inside-machine-learning/what-is-a-transformer-d07dd1fbec04
Transformers – Towards Data Science
https://towardsdatascience.com/transformers-141e32e69591
9.3. Transformer — Dive into Deep Learning 0.7 documentation
https://d2l.ai/chapter_attention-mechanism/transformer.html
The Annotated Transformer
http://nlp.seas.harvard.edu/2018/04/03/attention.html
# skip connection
Understanding LSTM Networks -- colah's blog
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
# layer normalization
The Star Also Rises Normalization
https://hemingwang.blogspot.com/2019/10/normalization.html
# layer normalization
Weight Normalization and Layer Normalization Explained (Normalization in Deep Learning Part 2) _ Machine Learning Explained
https://mlexplained.com/2018/01/13/weight-normalization-and-layer-normalization-explained-normalization-in-deep-learning-part-2/
# softmax
Softmax - Hands-On Natural Language Processing with Python [Book]
https://www.oreilly.com/library/view/hands-on-natural-language/9781789139495/3550f443-190d-4931-8d57-29db02a3abff.xhtml
-----
◎ 日文參考資料
論文解説 Attention Is All You Need (Transformer) - ディープラーニングブログ
http://deeplearning.hatenablog.com/entry/transformer
# Masked
論文解説 Convolutional Sequence to Sequence Learning (ConvS2S) - ディープラーニングブログ
http://deeplearning.hatenablog.com/entry/convs2s
-----
◎ 簡體中文參考資料
一文读懂「Attention is All You Need」_ 附代码实现 _ 机器之心
https://www.jiqizhixin.com/articles/2018-01-10-20
tensor-to-tensor[理论篇] - daiwk-github博客
https://daiwk.github.io/posts/platform-tensor-to-tensor.html#422-attention
【NLP】Transformer详解 - 知乎
https://zhuanlan.zhihu.com/p/44121378
详解Transformer (Attention Is All You Need) - 知乎
https://zhuanlan.zhihu.com/p/48508221
《Attention is All You Need》浅读(简介+代码) - 科学空间|Scientific Spaces
https://kexue.fm/archives/4765
深度学习中的注意力模型(2017版) - 知乎
https://zhuanlan.zhihu.com/p/37601161
放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN_RNN_TF)比较 - 知乎
https://zhuanlan.zhihu.com/p/54743941
# Conv1
CNN网络中的 1 x 1 卷积是什么? - AI小作坊 的博客 - CSDN博客
https://blog.csdn.net/zhangjunhit/article/details/55101559
-----
◎ 繁體中文參考資料
Attention Is All You Need:基於注意力機制的機器翻譯模型 – Youngmi huang – Medium
https://medium.com/@cyeninesky3/attention-is-all-you-need-%E5%9F%BA%E6%96%BC%E6%B3%A8%E6%84%8F%E5%8A%9B%E6%A9%9F%E5%88%B6%E7%9A%84%E6%A9%9F%E5%99%A8%E7%BF%BB%E8%AD%AF%E6%A8%A1%E5%9E%8B-dcc12d251449
Seq2seq pay Attention to Self Attention Part 2(中文版)
https://medium.com/@bgg/seq2seq-pay-attention-to-self-attention-part-2-%E4%B8%AD%E6%96%87%E7%89%88-ef2ddf8597a4
Easy Introduction to Transformer - Jexus Scripts
https://voidism.github.io/note/2019/02/05/Transformer_Intro/
# masked
自迴歸模型 - 維基百科,自由的百科全書
https://zh.m.wikipedia.org/zh-tw/%E8%87%AA%E8%BF%B4%E6%AD%B8%E6%A8%A1%E5%9E%8B
-----
◎ 代碼實作
How to code The Transformer in Pytorch – Towards Data Science
https://towardsdatascience.com/how-to-code-the-transformer-in-pytorch-24db27c8f9ec
如何在CUDA中为Transformer编写一个PyTorch自定义层 _ 机器之心
https://www.jiqizhixin.com/articles/19032504
深度学习中的注意力模型(2017版) - 知乎
https://zhuanlan.zhihu.com/p/37601161
放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN_RNN_TF)比较 - 知乎
https://zhuanlan.zhihu.com/p/54743941
# Conv1
CNN网络中的 1 x 1 卷积是什么? - AI小作坊 的博客 - CSDN博客
https://blog.csdn.net/zhangjunhit/article/details/55101559
-----
◎ 繁體中文參考資料
Attention Is All You Need:基於注意力機制的機器翻譯模型 – Youngmi huang – Medium
https://medium.com/@cyeninesky3/attention-is-all-you-need-%E5%9F%BA%E6%96%BC%E6%B3%A8%E6%84%8F%E5%8A%9B%E6%A9%9F%E5%88%B6%E7%9A%84%E6%A9%9F%E5%99%A8%E7%BF%BB%E8%AD%AF%E6%A8%A1%E5%9E%8B-dcc12d251449
Seq2seq pay Attention to Self Attention Part 2(中文版)
https://medium.com/@bgg/seq2seq-pay-attention-to-self-attention-part-2-%E4%B8%AD%E6%96%87%E7%89%88-ef2ddf8597a4
Easy Introduction to Transformer - Jexus Scripts
https://voidism.github.io/note/2019/02/05/Transformer_Intro/
# masked
自迴歸模型 - 維基百科,自由的百科全書
https://zh.m.wikipedia.org/zh-tw/%E8%87%AA%E8%BF%B4%E6%AD%B8%E6%A8%A1%E5%9E%8B
-----
◎ 代碼實作
How to code The Transformer in Pytorch – Towards Data Science
https://towardsdatascience.com/how-to-code-the-transformer-in-pytorch-24db27c8f9ec
如何在CUDA中为Transformer编写一个PyTorch自定义层 _ 机器之心
https://www.jiqizhixin.com/articles/19032504
No comments:
Post a Comment