[翻譯] Understanding LSTM Networks
2019/09/10
-----
Recurrent Neural Networks
-----
Humans don’t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking from scratch again. Your thoughts have persistence.
人們不會時時從頭開始思考。當你閱讀這篇文章時,你會根據你對之前單詞的理解來理解每個單詞。 你不會扔掉所有東西,然後再從頭開始思考。 你的思考會一直持續。
-----
Traditional neural networks can’t do this, and it seems like a major shortcoming. For example, imagine you want to classify what kind of event is happening at every point in a movie. It’s unclear how a traditional neural network could use its reasoning about previous events in the film to inform later ones.
傳統的神經網路無法做到這一點,這似乎是一個主要的缺點。 例如,假設您想要對電影中每個點發生的事件進行分類。 目前尚不清楚傳統神經網路如何利用其對電影中先前事件的推理來告知後者。
-----
Recurrent neural networks address this issue. They are networks with loops in them, allowing information to persist.
循環神經網路解決了這個問題。 它們是帶有迴圈的網絡,允許信息持續保存。
-----

Fig. 1. Recurrent Neural Networks have loops [1].
-----
In the above diagram, a chunk of neural network, A, looks at some input xt and outputs a value ht. A loop allows information to be passed from one step of the network to the next.
在上圖中,一塊神經網路 A 查看一些輸入 xt 並輸出一個值 ht。迴圈允許信息從網路的一個步驟傳遞到下一個步驟。
-----
These loops make recurrent neural networks seem kind of mysterious. However, if you think a bit more, it turns out that they aren’t all that different than a normal neural network. A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor. Consider what happens if we unroll the loop:
這些迴圈使得循環神經網路看起來有點神秘。但是,如果你多想一下,事實證明它們與普通的神經網路並沒有什麼不同。 可以將循環神經網路視為同一網路的多個副本,每個副本都將消息傳遞給後繼者。 考慮如果我們展開迴圈會發生什麼:
-----

Fig. 2. An unrolled recurrent neural network [1].
-----
This chain-like nature reveals that recurrent neural networks are intimately related to sequences and lists. They’re the natural architecture of neural network to use for such data.
這種類似鏈的性質表明,遞歸神經網路與序列和列表密切相關。 它們是用於此類數據的神經網路的自然架構。
-----
And they certainly are used! In the last few years, there have been incredible success applying RNNs to a variety of problems: speech recognition, language modeling, translation, image captioning… The list goes on. I’ll leave discussion of the amazing feats one can achieve with RNNs to Andrej Karpathy’s excellent blog post, The Unreasonable Effectiveness of Recurrent Neural Networks. But they really are pretty amazing.
他們肯定會被使用! 在過去幾年中,將 RNN 應用於各種問題取得了令人難以置信的成功:語音識別,語言建模,翻譯,圖像字幕 ...... 這個列表還在繼續。 我將討論使用 RNNs 可以實現的驚人壯舉,以及 Andrej Karpathy 的優秀部落格文章,回歸神經網路不合理的有效性。 但他們真的很棒。
-----
Essential to these successes is the use of “LSTMs,” a very special kind of recurrent neural network which works, for many tasks, much much better than the standard version. Almost all exciting results based on recurrent neural networks are achieved with them. It’s these LSTMs that this essay will explore.
這些成功的關鍵在於使用“LSTM”,這是一種非常特殊的遞歸神經網路,對於許多任務而言,它比標準版本好得多。 幾乎所有基於遞歸神經網路的令人興奮的結果都是用它們實現的。 這篇文章會探討這些 LSTM。
-----
The Problem of Long-Term Dependencies
-----
One of the appeals of RNNs is the idea that they might be able to connect previous information to the present task, such as using previous video frames might inform the understanding of the present frame. If RNNs could do this, they’d be extremely useful. But can they? It depends.
RNN 的一個吸引力是他們可能能夠將先前信息連接到當前任務,例如使用先前的視頻幀可能通知對當前幀的理解。 如果 RNN 可以做到這一點,它們將非常有用。 但他們可以嗎? 看看吧。
-----
Sometimes, we only need to look at recent information to perform the present task. For example, consider a language model trying to predict the next word based on the previous ones. If we are trying to predict the last word in “the clouds are in the sky,” we don’t need any further context – it’s pretty obvious the next word is going to be sky. In such cases, where the gap between the relevant information and the place that it’s needed is small, RNNs can learn to use the past information.
有時,我們只需要查看最近的信息來執行當前任務。 例如,考慮一種語言模型,試圖根據之前的單詞預測下一個單詞。 如果我們試圖預測“雲在天空中”的最後一個詞,我們不需要任何進一步的背景 - 很明顯下一個詞將是天空。 在這種情況下,如果相關信息與所需信息之間的差距很小,則 RNN 可以學習使用過去的信息。
-----
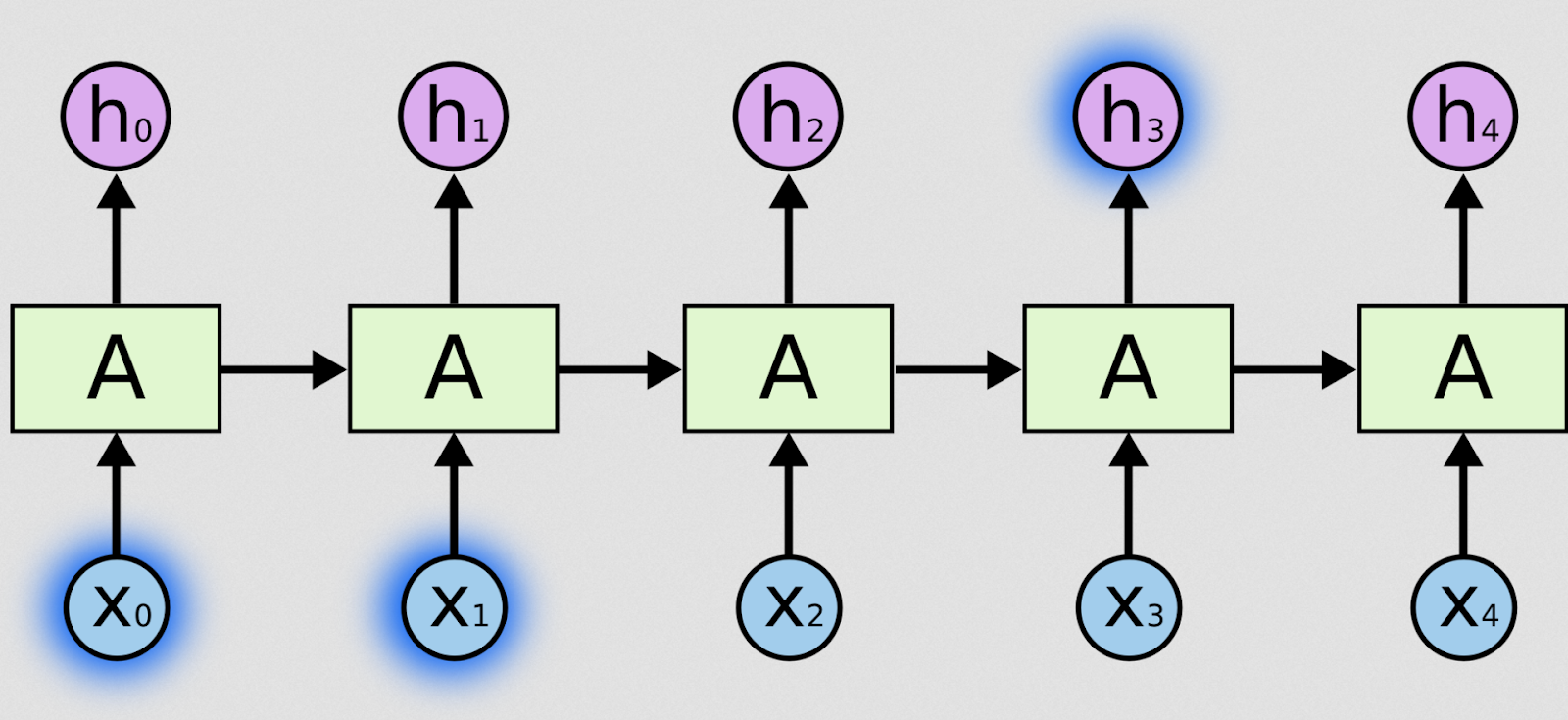
Fig. 3. RNNs can learn to use the past information [1].
-----
But there are also cases where we need more context. Consider trying to predict the last word in the text “I grew up in France… I speak fluent French.” Recent information suggests that the next word is probably the name of a language, but if we want to narrow down which language, we need the context of France, from further back. It’s entirely possible for the gap between the relevant information and the point where it is needed to become very large.
但也有一些情況需要更多的背景。 考慮嘗試預測文本中的最後一個詞“我在法國長大......我說流利的法語。”最近的信息表明,下一個詞可能是一種語言的名稱,但如果我們想縮小哪種語言,我們需要從更進一步的背景來看,法國的背景。 相關信息與需要變得非常大的點之間的差距是完全可能的。
-----
Unfortunately, as that gap grows, RNNs become unable to learn to connect the information.
不幸的是,隨著差距的擴大,RNN 無法學習連接信息。
-----

Fig. 4. Unfortunately, as that gap grows, RNNs become unable to learn to connect the information [1].
-----
In theory, RNNs are absolutely capable of handling such “long-term dependencies.” A human could carefully pick parameters for them to solve toy problems of this form. Sadly, in practice, RNNs don’t seem to be able to learn them. The problem was explored in depth by Hochreiter (1991) [German] and Bengio, et al. (1994), who found some pretty fundamental reasons why it might be difficult.
理論上,RNN 絕對能夠處理這種“長期依賴性”。人類可以仔細挑選參數來解決這種形式的玩具問題。 遺憾的是,在實踐中,RNN 似乎無法學習它們。 Hochreiter(1991)[德文] 和 Bengio 等人對該問題進行了深入探討(1994),他們找到了一些非常根本的原因,為什麼它可能很難。
-----
Thankfully, LSTMs don’t have this problem!
值得慶幸的是,LSTM 沒有這個問題!
-----
LSTM Networks
-----
Long Short Term Memory networks – usually just called “LSTMs” – are a special kind of RNN, capable of learning long-term dependencies. They were introduced by Hochreiter & Schmidhuber (1997), and were refined and popularized by many people in following work.1 They work tremendously well on a large variety of problems, and are now widely used.
長短期內存網絡 - 通常只稱為“LSTM” - 是一種特殊的 RNN,能夠學習長期依賴性。 它們是由 Hochreiter&Schmidhuber(1997)介紹的,並且在下面的工作中被許多人精煉和推廣 [備註1]。他們在各種各樣的問題上表現得非常好,現在被廣泛使用。
-----
LSTMs are explicitly designed to avoid the long-term dependency problem. Remembering information for long periods of time is practically their default behavior, not something they struggle to learn!
LSTM 明確旨在避免長期依賴性問題。 長時間記住信息實際上是他們的預設行為,而不是他們難以學習的東西!
-----
All recurrent neural networks have the form of a chain of repeating modules of neural network. In standard RNNs, this repeating module will have a very simple structure, such as a single tanh layer.
所有遞歸神經網絡都具有神經網絡重複模塊鏈的形式。 在標準 RNN 中,該重複模塊將具有非常簡單的結構,例如單個 tanh 層。
-----

Fig. 5. The repeating module in a standard RNN contains a single layer [1].
-----
LSTMs also have this chain like structure, but the repeating module has a different structure. Instead of having a single neural network layer, there are four, interacting in a very special way.
LSTM 也具有這種類似鏈的結構,但重複模塊具有不同的結構。 有四個,而不是一個神經網絡層,以一種非常特殊的方式進行交互。
-----

Fig. 6. The repeating module in an LSTM contains four interacting layers [1].
-----
Don’t worry about the details of what’s going on. We’ll walk through the LSTM diagram step by step later. For now, let’s just try to get comfortable with the notation we’ll be using.
不要擔心發生了什麼的細節。 我們將逐步介紹 LSTM 圖。 現在,讓我們試著對我們將要使用的符號感到滿意。
-----

Fig. 7. Each line carries an entire vector, from the output of one node to the inputs of others [1].
-----
In the above diagram, each line carries an entire vector, from the output of one node to the inputs of others. The pink circles represent pointwise operations, like vector addition, while the yellow boxes are learned neural network layers. Lines merging denote concatenation, while a line forking denote its content being copied and the copies going to different locations.
在上圖中,每一行都攜帶一個整個向量,從一個節點的輸出到其他節點的輸入。 粉色圓圈表示逐點運算,如矢量加法,而黃色框表示神經網絡層。 行合併表示連接,而行分叉表示其內容被複製,副本將轉移到不同的位置。
-----
The Core Idea Behind LSTMs
-----
The key to LSTMs is the cell state, the horizontal line running through the top of the diagram.
LSTM 的關鍵是單元狀態,貫穿圖頂部的水平線。
-----
The cell state is kind of like a conveyor belt. It runs straight down the entire chain, with only some minor linear interactions. It’s very easy for information to just flow along it unchanged.
單元狀態有點像傳送帶。 它直接沿著整個鏈運行,只有一些次要的線性交互。 信息很容易沿著它不變地流動。
-----

Fig. 8. The cell state is kind of like a conveyor belt [1].
-----
The LSTM does have the ability to remove or add information to the cell state, carefully regulated by structures called gates.
LSTM 確實能夠移除或添加信息到單元狀態,由稱為門的結構精心調節。
-----
Gates are a way to optionally let information through. They are composed out of a sigmoid neural net layer and a pointwise multiplication operation.
門可選擇信息通過的方式。這些門由 sigmoid 神經網路層和點乘運算組成。
-----

Fig. 9. The sigmoid layer outputs numbers between zero and one [1].
-----
The sigmoid layer outputs numbers between zero and one, describing how much of each component should be let through. A value of zero means “let nothing through,” while a value of one means “let everything through!”
Sigmoid 層輸出 0 到 1 之間的數字,描述每個組件應該通過多少。 值為 0 意味著“不讓任何東西通過”,而值為 1 則意味著“讓一切都通過!”
-----
An LSTM has three of these gates, to protect and control the cell state.
LSTM 具有三個這樣的門,用於保護和控制單元狀態。
-----
Step-by-Step LSTM Walk Through
-----
The first step in our LSTM is to decide what information we’re going to throw away from the cell state. This decision is made by a sigmoid layer called the “forget gate layer.” It looks at ht−1 and xt, and outputs a number between 0 and 1 for each number in the cell state Ct−1. A 1 represents “completely keep this” while a 0 represents “completely get rid of this.”
我們的 LSTM 的第一步是確定我們將從細胞狀態中丟棄哪些信息。 該判定由稱為“遺忘門層”的S形層決定。它查看 ht-1 和 xt,並為單元狀態 Ct-1 中的每個數字輸出 0 到 1 之間的數字。 1 代表“完全保持這個”,而 0 代表“完全擺脫這個”。
Let’s go back to our example of a language model trying to predict the next word based on all the previous ones. In such a problem, the cell state might include the gender of the present subject, so that the correct pronouns can be used. When we see a new subject, we want to forget the gender of the old subject.
讓我們回到我們的語言模型示例,試圖根據以前的所有單詞預測下一個單詞。 在這樣的問題中,細胞狀態可能包括當前受試者的性別,因此可以使用正確的代詞。 當我們看到一個新主題時,我們想要忘記舊主題的性別。
-----

Fig. 10. Forget gate [1].
-----
The next step is to decide what new information we’re going to store in the cell state. This has two parts. First, a sigmoid layer called the “input gate layer” decides which values we’ll update. Next, a tanh layer creates a vector of new candidate values, C~t, that could be added to the state. In the next step, we’ll combine these two to create an update to the state.
下一步是確定我們將在單元狀態中存儲哪些新信息。 這有兩個部分。 首先,稱為“輸入門層”的 sigmoid 層決定我們將更新哪些值。 接下來,tanh 層創建可以添加到狀態的新候選值 C~t 的向量。 在下一步中,我們將結合這兩個來創建狀態更新。
-----
In the example of our language model, we’d want to add the gender of the new subject to the cell state, to replace the old one we’re forgetting.
在我們的語言模型的例子中,我們想要將新主題的性別添加到單元格狀態,以替換我們忘記的舊主題。
-----

Fig.11. Input gate [1].
-----
It’s now time to update the old cell state, Ct−1, into the new cell state Ct. The previous steps already decided what to do, we just need to actually do it.
現在是時候將舊的單元狀態 Ct-1 更新為新的單元狀態 Ct。 之前的步驟已經決定要做什麼,我們只需要實際做到這一點。
-----
We multiply the old state by ft, forgetting the things we decided to forget earlier. Then we add it∗C~t. This is the new candidate values, scaled by how much we decided to update each state value.
我們將舊狀態乘以 ft,忘記我們之前決定忘記的事情。 然後我們添加 * C~t。 這是新的候選值,根據我們決定更新每個州的值來縮放。
-----
In the case of the language model, this is where we’d actually drop the information about the old subject’s gender and add the new information, as we decided in the previous steps.
在語言模型的情況下,我們實際上放棄了關於舊主題的性別的信息並添加新信息,正如我們在前面的步驟中所做的那樣。
-----

Fig. 12. Cell state [1].
-----
Finally, we need to decide what we’re going to output. This output will be based on our cell state, but will be a filtered version. First, we run a sigmoid layer which decides what parts of the cell state we’re going to output. Then, we put the cell state through tanh (to push the values to be between −1 and 1) and multiply it by the output of the sigmoid gate, so that we only output the parts we decided to.
最後,我們需要決定我們要輸出的內容。 此輸出將基於我們的單元狀態,但將是過濾版本。 首先,我們運行一個 sigmoid 層,它決定我們要輸出的單元狀態的哪些部分。 然後,我們將單元狀態設置為 tanh(將值推到介於 -1 和 1 之間)並將其乘以 sigmoid 門的輸出,以便我們只輸出我們決定的部分。
-----
For the language model example, since it just saw a subject, it might want to output information relevant to a verb, in case that’s what is coming next. For example, it might output whether the subject is singular or plural, so that we know what form a verb should be conjugated into if that’s what follows next.
對於語言模型示例,由於它只是看到一個主題,它可能想要輸出與動詞相關的信息,以防接下來會發生什麼。 例如,它可能輸出主語是單數還是複數,以便我們知道動詞應該與什麼形式共軛,如果接下來的話。
-----

Fig. 13. Output gate [1].
-----
Variants on Long Short Term Memory
-----
What I’ve described so far is a pretty normal LSTM. But not all LSTMs are the same as the above. In fact, it seems like almost every paper involving LSTMs uses a slightly different version. The differences are minor, but it’s worth mentioning some of them.
到目前為止我所描述的是一個非常正常的 LSTM。 但並非所有 LSTM 都與上述相同。 事實上,似乎幾乎所有涉及 LSTM 的論文都使用略有不同的版本。 差異很小,但值得一提的是其中一些。
-----
One popular LSTM variant, introduced by Gers & Schmidhuber (2000), is adding “peephole connections.” This means that we let the gate layers look at the cell state.
由 Gers& Schmidhuber(2000)引入的一種流行的 LSTM 變體是添加“窺視孔連接”。這意味著我們讓柵極層看到單元狀態。
-----

Fig. 14. Peephole connections [1].
-----
The above diagram adds peepholes to all the gates, but many papers will give some peepholes and not others.
上面的圖表為所有門增加了窺視孔,但許多論文會給一些窺視孔而不是其他的。
-----
Another variation is to use coupled forget and input gates. Instead of separately deciding what to forget and what we should add new information to, we make those decisions together. We only forget when we’re going to input something in its place. We only input new values to the state when we forget something older.
另一種變化是使用耦合的遺忘和輸入門。 我們不是單獨決定忘記什麼以及應該添加新信息,而是共同做出這些決定。 我們只會忘記當我們要在其位置輸入內容時。 當我們忘記舊事物時,我們只向狀態輸入新值。
-----

Fig. 15. Coupled forget and input gates [1].
-----
A slightly more dramatic variation on the LSTM is the Gated Recurrent Unit, or GRU, introduced by Cho, et al. (2014). It combines the forget and input gates into a single “update gate.” It also merges the cell state and hidden state, and makes some other changes. The resulting model is simpler than standard LSTM models, and has been growing increasingly popular.
LSTM 稍微有點戲劇性的變化是由 Cho 等人引入的門控循環單元(GRU)。(2014)。 它將遺忘和輸入門組合成一個“更新門”。它還合併了單元狀態和隱藏狀態,並進行了一些其他更改。 由此產生的模型比標準 LSTM 模型簡單,並且越來越受歡迎。
-----

Fig. 16. GRU [1].
-----
These are only a few of the most notable LSTM variants. There are lots of others, like Depth Gated RNNs by Yao, et al. (2015). There’s also some completely different approach to tackling long-term dependencies, like Clockwork RNNs by Koutnik, et al. (2014).
這些只是最著名的 LSTM 變種中的一小部分。 還有很多其他的東西,比如Y ao等人的 Depth Gated RNNs。(2015年)。 還有一些完全不同的解決長期依賴關係的方法,如 Koutnik 等人的 Clockwork RNNs。(2014)。
-----
Which of these variants is best? Do the differences matter? Greff, et al. (2015) do a nice comparison of popular variants, finding that they’re all about the same. Jozefowicz, et al. (2015) tested more than ten thousand RNN architectures, finding some that worked better than LSTMs on certain tasks.
哪種變體最好? 差異是否重要? 格雷夫等人。 (2015)對流行的變種做了很好的比較,發現它們都差不多。 Jozefowicz,et al。 (2015)測試了超過一萬個RNN架構,找到了一些在某些任務上比 LSTM 更好的架構。
-----
Conclusion
-----
Earlier, I mentioned the remarkable results people are achieving with RNNs. Essentially all of these are achieved using LSTMs. They really work a lot better for most tasks!
早些時候,我提到了人們使用 RNN 取得的顯著成果。 基本上所有這些都是使用 LSTM 實現的。 對於大多數任務來說,它們確實工作得更好!
-----
Written down as a set of equations, LSTMs look pretty intimidating. Hopefully, walking through them step by step in this essay has made them a bit more approachable.
寫下來作為一組方程式,LSTM 看起來非常令人生畏。 希望在這篇文章中逐步走過它們,使它們更加平易近人。
-----
LSTMs were a big step in what we can accomplish with RNNs. It’s natural to wonder: is there another big step? A common opinion among researchers is: “Yes! There is a next step and it’s attention!” The idea is to let every step of an RNN pick information to look at from some larger collection of information. For example, if you are using an RNN to create a caption describing an image, it might pick a part of the image to look at for every word it outputs. In fact, Xu, et al. (2015) do exactly this – it might be a fun starting point if you want to explore attention! There’s been a number of really exciting results using attention, and it seems like a lot more are around the corner…
LSTM 是我們通過 RNN 實現的重要一步。 很自然地想知道:還有另一個重要的步驟嗎? 研究人員的共同觀點是:“是的! 下一步是它的注意力!“我們的想法是讓 RNN 的每一步都從一些更大的信息集中選擇信息。 例如,如果您使用 RNN 創建描述圖像的標題,則可能會選擇圖像的一部分來查看其輸出的每個單詞。 實際上,徐等人。 (2015)做到這一點 - 如果你想探索注意力,它可能是一個有趣的起點! 使用注意力已經取得了許多非常令人興奮的結果,而且似乎還有很多事情即將來臨......
-----
Attention isn’t the only exciting thread in RNN research. For example, Grid LSTMs by Kalchbrenner, et al. (2015) seem extremely promising. Work using RNNs in generative models – such as Gregor, et al. (2015), Chung, et al. (2015), or Bayer & Osendorfer (2015) – also seems very interesting. The last few years have been an exciting time for recurrent neural networks, and the coming ones promise to only be more so!
注意力不是 RNN 研究中唯一激動人心的線索。 例如,Kalchbrenner 等人的 Grid LSTMs。 (2015)似乎非常有希望。 在生成模型中使用 RNN 的工作 - 例如 Gregor,et al。 (2015),Chung,et al。 (2015年),或 Bayer&Osendorfer(2015年) - 似乎也很有趣。 過去幾年對於遞歸神經網絡來說是一個激動人心的時刻,即將到來的神經網絡承諾只會更加激動人心!
-----
References
[1] Understanding LSTM Networks -- colah's blog
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[2] LSTM论文翻译-《Understanding LSTM Networks》 - 老笨妞 - CSDN博客
https://blog.csdn.net/juanjuan1314/article/details/52020607
[3] LSTM
No comments:
Post a Comment