AI 從頭學(三六):YOLO v1
2018/05/21
前言:
YOLO 可說是 object detection 第一個成功的 end-to-end(整合良好,不是好幾個演算法湊成一個)的演算法。而後的 YOLO v2 與 v3 更在效能與準確率都取得了極大的成功。本文簡介 YOLO v1 的架構與原理。
-----
Summary:
在學習 YOLO [1], [2] 之前,必須對 mAP [3] 與 NMS [4] 有基本的認識,才能夠進一步探討 YOLO 這個 object detection 演算法。本文參考了網路上 YOLO 的說明文章 [5]-[16] 與程式碼[17]-[21]。最後說明為何使用 Leaky ReLU 這個 activation function [22]-[24]。
-----
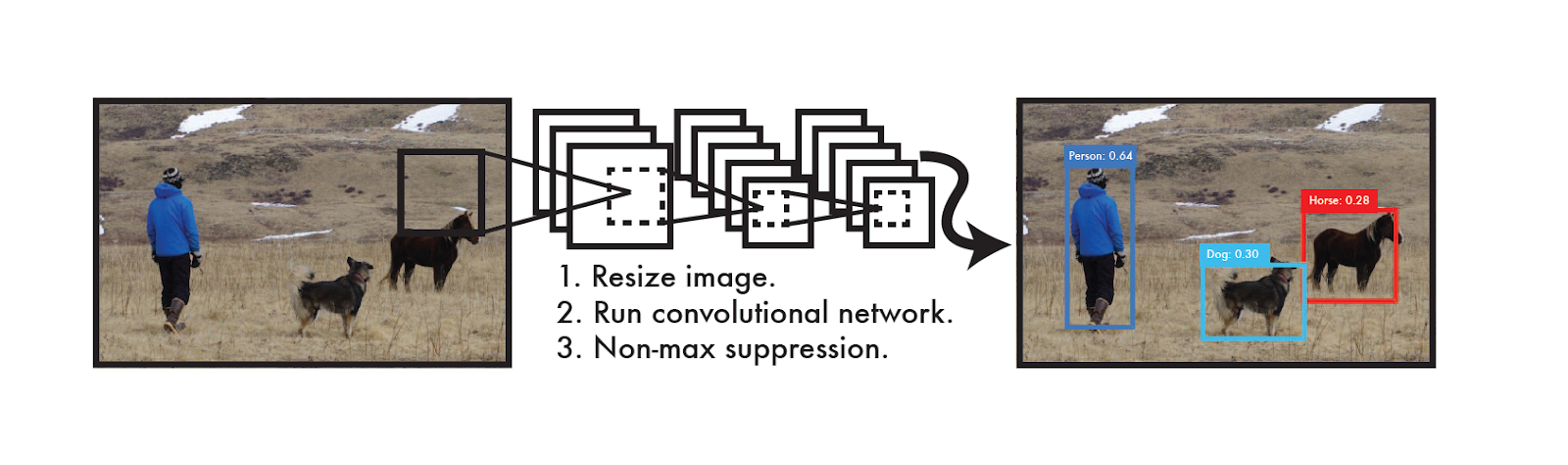
Fig. 1. The YOLO Detection System [1].
-----
Outline
一、YOLO
二、Model
三、Loss Function
四、NMS
五、Leaky ReLU
-----
一、YOLO
YOLO 這個 object detection 的演算法主要可分為三個步驟。第一、輸入的圖片先把它更新到 448x448 的正方形大小。第二、整張圖片放入一個 CNN 網路運算。第三、演算法最後的輸出是幾個物件的中心、大小、與類別的 confidence。參考圖1,左邊 0.64 的可能是人,中間 0.30 的可能性是狗,右邊 0.28 的可能性是馬(示範圖片不能算是一個好的結果)。
-----
二、Model
YOLO 的作法是先把正方形平均分為 7x7 個小塊。每個小塊可以預測兩個物件框的中心位置、大小、與類別。限制條件是中心位置必須落在小塊裡面。
所以一開始的輸出會有 98 個可能物件,去掉無效的框框(演算法認為不是一個物體),然後透過 NMS [4] 把重複的物件去除。然後再根據這個物件框的最大可能類別,最後就是圖2右邊識別出來的三個物件。
圖2是模型的原理,可以搭配圖3.1與圖3.2一起理解。
首先分成 7x7 個小塊。每個小塊分別可以產生兩個建議框,資訊包含框的中心 (x, y)(必須落於小塊內)、框的寬高 w, h,以及框框是物件,或者非物件。如圖2中間上方所示。這 10 個 bytes 也就是圖3.1最後輸出的前十個資訊。
圖2中間下方則是每個小塊最有可能的類別(二十種其可信度最高者),類別的資訊是由上面的框框決定。這 20 個 bytes 也就是圖3.1最後輸出的後二十個資訊。二十個可信度由兩個框框共享,所以這小塊延伸的兩個框框預測的是同一種物件(可信度最高那種)。如果小塊內有兩個物件,那只能預測出比較大的那一個。
由圖2中間上方可以看到重複性非常高,所以 NMS 是很有必要的。

Fig. 2. The Model [1].
-----
三、Loss Function
Loss function 可說是整個 YOLO 演算法的重點。重點中的重點則在於圖3.1最右邊,CNN 的輸出。 也就是圖2在論文中的說明:S × S × (B * 5 + C) tensors。
S = 7。
B = 2。
C = 20。
S = 7,7 X 7 個預測框。B = 2,每個框預測 2 個物件(屬於同一種類別)。5 分別是中心 (x, y) 與寬高 w, h,以及是物件或不是物件。然後 C = 20 是這兩個物件屬於二十種類別的 confidences。

Fig. 3.1. The Architecture [1].
-----
如圖3.2,Loss function 希望中心點 (x, y) 要對(第一行)。框框 w, h 要 match(第二行),由於希望減低大框框位移錯誤的比重,所以加上根號 [6], [7], [10], [11]。這個參考圖3.4很容易理解,小 box 的橫軸值較小,發生偏移時,反應到 y 軸上相比大 box 要大 [7]。第三、四行分別為框框被判定是物件還是非物件,非物件重要性降低,係數設為0.5。另外,座標的重要性比較高,係數設為5,如圖3.3所說明。最後則是分類(第五行)。
這邊有個補充,Sheng-min Huang:「7*7 所以會有 49個 cells,x, y 其實只有在算物件在這一格 cell 裡的位置,真正圖裡的位置要先找出 cell 的位置再加上 x, y。」
基本上,就是希望透過訓練集的資料更新網路的 weighting values,以達到較小的誤差值。這跟一般 CNN 沒有不同,只是 YOLO 連物件座標都預測了!

Fig. 3.2. Loss function [1].

Fig. 3.3. Parameters [1].

Fig. 3.4. Root function [7].
-----
四、NMS
比較特別的一點是,圖3.1的網路輸出之後,要先經過 NMS 去除重複的物件,然後再計算第三節的 loss。
「接下來,我們要去解析網絡的預測結果,這裡採用了第一種預測策略,即判斷預測框類別,再 NMS,多虧了 TF 提供了 NMS 的函數 tf.image.non_max_suppression,其實實現起來很簡單,所有的細節前面已經交代了。」[17]
-----
五、Leaky ReLU
在 AlexNet 大獲成功之後,ReLU 廣受歡迎,YOLO 使用更新的 Leaky ReLU [22]-[24]。
因為「ReLU 會使部分神經元的輸出為0,可以讓神經網路變得稀疏,緩解過度擬合的問題。但衍生出另一個問題是,如果把一個神經元停止後,就難以再次開啟(Dead ReLU Problem),因此又有 Leaky ReLU 類等方法」來解決這個問題 [22]。
-----
結論:
YOLO 這篇論文前後看了很久,但只要先搞清楚 mAP、NMS,那 YOLO 其實只是利用 CNN 同時判斷框框的位置與大小。講是容易,但能夠想到這一層,YOLO 可說是天才之作。
-----
References
[1] Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf[2] YOLO论文翻译——中文版
http://noahsnail.com/2017/08/02/2017-8-2-YOLO%E8%AE%BA%E6%96%87%E7%BF%BB%E8%AF%91%E2%80%94%E2%80%94%E4%B8%AD%E6%96%87%E7%89%88/
[3] Machine Learning Concept(一):Mean Average Precision(mAP)
http://hemingwang.blogspot.tw/2018/04/machine-learning-conceptmean-average.html
[4] Machine Learning Concept(二):Non-Maximum Suppression(NMS)
http://hemingwang.blogspot.tw/2018/04/machine-learning-conceptnon-maximum.html
-----
基本說明
[5] YOLO — You Only Look Once 介紹 – Chenchou LO – Medium
https://medium.com/@chenchoulo/yolo-%E4%BB%8B%E7%B4%B9-4307e79524fe
[6] 论文阅读笔记:You Only Look Once Unified, Real-Time Object Detection - CSDN博客
https://blog.csdn.net/tangwei2014/article/details/50915317
[7] 图解YOLO
https://zhuanlan.zhihu.com/p/24916786
[8] YOLO详解
https://zhuanlan.zhihu.com/p/25236464
[9] YOLO模型原理-大数据算法
http://x-algo.cn/index.php/2017/02/28/1767/
[10] You Only Look Once Unified, Real-Time Object Detection(YOLO)
https://zhuanlan.zhihu.com/p/31427164
[11] RCNN学习笔记(6):You Only Look Once(YOLO) Unified, Real-Time Object Detection - CSDN博客
https://blog.csdn.net/u011534057/article/details/51244354
-----
非基本說明
[12] 深度学习之目标检测-YOLO算法(一) – Eric Fan
https://www.fanyeong.com/2018/01/30/cnn-object-detection-yolo-part1/
[13] 深度学习之目标检测-YOLO算法(二) – Eric Fan
https://www.fanyeong.com/2018/01/31/cnn-object-detection-yolo-part2/
[14] YOLO解读 - 任广辉的博客 _ Sundrops Blog
http://renguanghui.com/2017/11/30/yolo/
[15] IOU
DEEP LEARNING之三十六:YOLO 算法(You Only Look Once) – Rethink
http://www.rethink.fun/index.php/2018/03/05/deep-learning36/
[16] C4W3L09 YOLO Algorithm - YouTube
https://www.youtube.com/watch?v=9s_FpMpdYW8
-----
代碼
[17] YOLO算法的原理与实现 - 云+社区 - 腾讯云
https://cloud.tencent.com/developer/article/1052865
[18] YOLO,一种简易快捷的目标检测算法 _ 雷锋网
https://www.leiphone.com/news/201801/VfYDZHC7Xa6hJXEK.html
[19] GitHub - MashiMaroLjc_YOLO implement the YOLO algorithm using MXNet_Gluon
https://github.com/MashiMaroLjc/YOLO
[20] Darknet Open Source Neural Networks in C
https://pjreddie.com/darknet/
[21] GitHub - pjreddie_darknet Convolutional Neural Networks
https://github.com/pjreddie/darknet
-----
Leaky ReLU
[22] 深度學習:使用激勵函數的目的、如何選擇激勵函數 Deep Learning the role of the activation function _ Mr. Opengate
http://mropengate.blogspot.tw/2017/02/deep-learning-role-of-activation.html
[23] cs231n_2017_lecture6
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture6.pdf
[24] Ramachandran, Prajit, Barret Zoph, and Quoc V. Le. "Searching for activation functions." (2018).
https://openreview.net/pdf?id=Hkuq2EkPf https://arxiv.org/pdf/1710.05941.pdf
No comments:
Post a Comment