AI 從頭學(一九):Recurrent Neural Network
2017/03/28
前言:
在一連串的 BP、AD、LeNet、CNN 等簡介之後,這次講了 RNN 三種基本架構。我想讀者,包括我自己,應該都能對 Deep Learning 有初步的掌握。
祝大家百丈礦脈,更深一層!
-----

Fig. Chain(圖片來源:Pixabay)。
-----
Summary:
Recurrent Neural Network (RNN) [1], [2] 主要可分為 RNN、Long Short-Term Memory (LSTM) LSTM、Gated Recurrent Unit (GRU) 三種 [3]-[8]。
傳統的RNN [9]-[12] 使用 Back Propagation Through Time (BPTT) Algorithm [13], [14]。有別於 BP Algorithm [15],BPTT是有序的,也就是往回調整參數權重時,同一層裡面,要從後面的輸出開始微分 [16], [17]。
LSTM [18]-[26] 增加了三個控制閘,藉以修正傳統RNN單元梯度陡峭與平緩的問題。GRU [27]-[33] 則是 LSTM 的簡化版,有較高的效能 [34], [35]。不管是 LSTM 或 GRU,都是藉由增加控制訊號來加強記憶 [36], [37]。
-----
第一節:RNN 與 LSTM 簡介
◎ RNN
圖1.1a 左邊是一個傳統的 FNN,右邊是 RNN,RNN 展開後得到圖1.1b。RNN 的公式見圖1.2a。
由圖1.1a 右可以看到,在 activation function(i.e. ht)傳遞到輸出層的同時,會順便傳相同的值回到ht,但時間上已經延後一個單位。所以我們看到圖1.1b,每一個 ht 作用時,要先將前一個 ht-1 的輸出乘上 W 的權重,加上輸入值 xt 乘上 Y 的權重,加上偏壓 b。這個是圖1.2a 的第一行。
後續作用 tanh,這個ht的值一邊往輸出層移動,一邊輸出到下一個 ht+1。這是第二行。
ht 乘上 V 的權重,加上偏壓 c,就成了輸出 ot。這是第三行。
瞧,RNN的觀念是不是很簡單。
值的一提的是圖1.2b,softmax function。這個只會用在輸出層,不會用在隱藏層。Softmax 主要的功能是使輸出成為一個離散的機率分佈,總和為 1。
-----

Fig. 1.1a. FNN and RNN, p. 4, [2].
-----

Fig. 1.1b. An unrolled RNN, p. 4, [2].
-----

Fig. 1.2a. RNN formula, p. 4, [2].
-----

Fig. 1.2b. Softmax function, p. 4, [2].
-----
◎ LSTM
在 [2] 裡面也提到了 LSTM,有公式(參考圖1.4),但沒有圖。圖的話,[1] 裡面有一張(參考圖1.3a),看起來很有學問,但是我建議你不要花太多時間,因為後面有更好的圖。而且在你還搞不清輸入跟乘法還有sigm以及tanh的作用之前,很難看懂。
本篇文章,關於 LSTM 最好的圖應該是圖1.3b,雖然它沒有標示三個閘,哪個是哪個,但是等你明瞭原理,其實一目瞭然,有沒有標示已經無關緊要了。
接下來則以 [2] 的公式(圖1.4)配合 [5] 的圖(圖1.3b)講解 LSTM。這個有點長,所以依照慣例,我們還是先來一段自問自答。圖跟公式沒有統一,這裡我們以圖為主好了。
-----
Question
Q1: σ, sigmoid
Q2: tanh, hyperbolic tangent
Q3: element-wise mul
Q4: f, forget gate
Q5: o, output gate
Q6: z, input
Q7: i, input gate
Q8: ct-1, old memory cell
Q9, ct, memory cell
-----
Q1: σ, sigmoid
這個 sigmoid function,並不像之前的 CNN 範例,以此作為 activation function。它主要的功能,是把值限定在0與1之前,然後可以當作控制訊號。配合乘法使用,如果乘以0就是資料訊號不通過,1就是全部通過,其他則是部分通過。所以我們看到圖1.3b中共有三個sigms,分別是忘記閘、輸入閘,以及輸出閘。編號分別是0、1、3。這個你在圖1.3a中是看不到的。
-----
Q2: tanh, hyperbolic tangent
這個就是一般的 activation function 囉。這個在圖1.3b中有兩個。左邊這個五角形可以知道編號2接的不是閘,而是真正的輸入。這個輸入要加上之前的記憶ct-1乘上忘記閘的值,然後準備輸出。以白話來說,就是首先由忘記閘0決定要忘掉多少東西,然後這次帶來的東西由輸入閘1決定要帶入多少東西,這兩個加總,準備輸出。
經過右邊的五角形 tanh 作用後,再由輸出閘3決定真正要輸出多少訊號量。
講到這邊,其實已經把 LSTM 講完了。
-----
Q3: element-wise mul
這個是向量乘法,向量,可以參考圖4.2b,字串也是一種向量。在此處,我建議你只要知道,這個就是乘以sigm輸出的0到1之間的值決定輸出的百分比。也就是控制的意思。
-----
Q4: f, forget gate
這個是編號0,用來決定上一個記憶ct-1可以進來多少。
-----
Q5: o, output gate
這個是編號3,用來決定真正要輸出多少。
-----
Q6: z, input
這個是編號2,就是真正的輸入值 xt 囉。它會另外拷貝三份給三個閘使用。
-----
Q7: i, input gate
這個是編號1,用來決定有多少輸入訊號 xt 可以進來。值得注意的是忘記閘與輸入閘都會被之前的記憶 ct-1 所影響。
-----
Q8: ct-1, old memory cell
之前保存的記憶。
-----
Q9, ct, memory cell
新的記憶,要帶到下一個運算 LSTM 運算單元。
-----

Fig. 1.3a. LSTM, p. 409, [1].
-----

Fig. 1.3b. LSTM, [5].
-----

Fig. 1.3c. LSTM symbols, [5].
-----
LSTM 公式:
本來圖講完,LSTM 的原理應該已經很清楚了,但是公式都貼出來了,所以還是配合圖講解一下公式好了。因為實作上還要把公式化為程式碼的。
公式在圖1.4。
有關 LSTM 的輸入,圖1.4a的第一行,xt=Wwet。可參考:word embedding matrix。
斯坦福大学深度学习与自然语言处理第二讲:词向量
http://www.52nlp.cn/%E6%96%AF%E5%9D%A6%E7%A6%8F%E5%A4%A7%E5%AD%A6%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%B8%8E%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86%E7%AC%AC%E4%BA%8C%E8%AE%B2%E8%AF%8D%E5%90%91%E9%87%8F
本節主要講解 LSTM 的結構,輸入的部分未來若有機會再專文討論。
-----

Fig. 1.4a. LSTM formula, p. 4, [2].
-----

Fig. 1.4b. LSTM formula, p. 4, [2].
-----

Fig. 1.4c. LSTM formula, p. 5, [2].
-----
第二節:RNN
◎ RNN
簡單的 RNN 架構在第一節已有說明。較複雜的 RNN 網路,請參考圖2,本文並不討論。
-----

Fig. 2.1a. An RNN is a very deep FNN, p. 2, [9].
-----

Fig. 2.1b. The Multiplicative RNN, p. 4, [9].
-----

Fig. 2.1c. Illustrations of four different RNNs, p. 4, [10].
-----
第三節:BPTT
◎ BPTT
「傳統的RNN [9]-[12] 使用 Back Propagation Through Time (BPTT) Algorithm [13], [14]。有別於 BP Algorithm [15],BPTT是有序的,也就是往回調整參數權重時,同一層裡面,要從後面的輸出開始微分 [16], [17]。」
這裡解釋一下上面這段話 :
基本上,類神經網路是一個函數,表現為網路的形式。網路有多個輸入,也有多個輸出。如果以類神經網路來解決問題,主要是要讓 cost function (C),或稱 loss function (L),也就是網路的輸出值與正確值的誤差越小越好。
當權重 w 與偏壓 b 固定時,函數為 f(x),輸入值為 x。但是當我們想要調整 w 與 b 使得誤差變小,這時 x 固定,w 跟 b 為函數 f 的變數,我們要對 C 做 w 與 b 的偏微分。當一階w偏導數大於0,表示誤差漸增,這時 w 要向左移動,誤差才會變小。這段話如果不很清楚,請重新看一下 [15]。
由於網路是多層的,所以微分時會遇到 chain rule。同一個輸出層,先做哪一個並不會影響結果。但是不同的隱藏層,要從輸出層一層一層往輸入層推進,這個部分是有序的。
RNN,如圖1.1b,看似一個扁平的網路,其實因為每個輸出都會受到之前的影響,所以做 BP的時候,要從後面的輸出往前做 BP,這也就是 RNN 用的 BP 叫做 back propagation through time 的意思,參考圖3.1a。原則上,你可以把簡單的RNN視為一個很深的網路。
[13] 的演算法不容易閱讀,[14] 則一目瞭然,參考圖3.1b。第一個部分是前向計算,變數t從1到T遞增。第二個部分是BPTT,變數t從T-1到1遞減。第三個部分則是更新權重。
-----

Fig. 3.1a. Back propagation through time, [17].
-----

Fig. 3.1b. BPTT algorithm, p. 243, [14].
-----
第四節:LSTM
◎ LSTM
LSTM 在第一節中其實已經講得很清楚,這裡多參考幾篇論文。
圖4.1a還算不錯。左邊是傳統的RNN,中間是 LSTM。展開後可得圖4.2b 跟4.2c。
參考右邊的解釋,你會知道有加法、乘法、sigm、tanh 等,也知道有三個閘,你知道它們之間有些關係與計算,但是輸入跟輸出都很難理解,所以還是圖1.3b比較好。
圖4.1b跟4.1c幫助都不是很大。但總之,到目前為止,靠著圖1.3b,你已經可以瞭解 LSTM 的架構。所以更複雜的圖4.1d與4.1e就請自行參考。
總之,主要是圖1.3b、4.2a、4.2d 三張圖,幫助我理解 LSTM。
-----

Fig. 4.1a. LSTM, p. 2, [23].
-----

Fig. 4.1b. LSTM, p. 274, [22].
-----

Fig. 4.1c. LSTM, p. 39, [21].
-----

Fig. 4.1d. An LSTM network, p. 40, [21].
-----

Fig. 4.1e. An LSTM network, p. 1745, [18].
-----

Fig. 4.2a. LSTM, [24].
-----

Fig. 4.2b. An LSTM network, [25].
-----

Fig. 4.2c. RNN, [26].
-----

Fig. 4.2d. LSTM, [26].
-----
第五節:GRU
◎ GRU
終於進到 GRU 了!
GRU 可以說是 LSTM 的簡化版。
圖5.1a 是 LSTM 跟 GRU 的「電路圖」。這兩個圖一開始一樣不容易看懂,特別 GRU 目前是全新的概念。
先看一下 LSTM。先注意有 foi 三個閘,閘有開關,你可以把黑點視為sigm。c~ 是新的記憶,由舊的記憶 c 加上輸入,這個舊的記憶 c 要先經由 f 決定剩下幾成,然後加上輸入的幾成,再存回 c 後,tanh,然後輸出閘,輸出。這個一樣越描越黑,有興趣可以配合其他的圖與公式仔細推敲。
LSTM 這邊就再講解一下圖5.2e的公式,主要是第五行,我做了小修改:
ct=(ct-1) x (ft) + (jt) x (it),參考圖5.1b。
ct-1是前一個記憶值。ft是忘記閘。
jt是輸入值。it是輸入閘。
其次是第六行:
ht=tanh(ct) x ot
ct 經過 activation function 之後,由輸出閘決定輸出的百分比。
至於前四行的 sigm 與 tanh 是怪怪的。
-----
這邊才是真正要講 GRU。
還是再來自問自答。
Question
Q10: 1-, interpolation
Q11: z, update gate
Q12: r, reset gate
Q13: h, activation
Q14: h~, candidate activation
-----
Q10: 1-, interpolation
先看一下圖5.1c,這個 1- ,是 interpolation。
在圖5.1a 右,這個閘顯示可以接左或接右。其實決定更新閘與重置閘的比率。舉例,一個是 60% 的資料可以通過,另一個就是 40% 的資料可以通過。
-----
Q11: z, update gate
z 決定有多少資料要更新。如果 z = 1,則全部都是舊資料,新資料完全不考慮進來。參考圖5.2f 的第四行公式。
-----
Q12: r, reset gate
r 是重置閘,它決定舊資料有多少比例進入成為新資料候選人。參考圖5.1a 右以及圖5.2f 的一、三行公式。
-----
Q13: h, activation
h是新資料,這個 activation function 是由更新閘決定多少比率的舊資料,與多少比率的新資料候選人,不是單純的 tanh。參考圖5.1a 右,以及圖5.2f 公式的第四行。
-----
Q14: h~, candidate activation
h~ 是新資料候選人。它是由重置閘先決定舊資料有多少比例進來,然後加上輸入資料,再由更新閘決定輸出。參考圖5.1a 右,以及圖5.2f 的三、四行。
-----
圖5.3 就請自行參考。
-----

Fig. 5.1a. LSTM and GRU, p. 3, [27].
-----

Fig. 5.1b. LSTM, p. 2, [28].
-----

Fig. 5.1c. GRU, p. 3, [28].
-----

Fig. 5.2a. GRU formula, p. 4, [27].
-----

Fig. 5.2b. GRU formula, p. 4, [27].
-----

Fig. 5.2c. GRU formula, p. 4, [27].
-----

Fig. 5.2d. GRU formula, p. 4, [27].
-----

Fig. 5.2e. LSTM formula, p. 2, [28].
-----
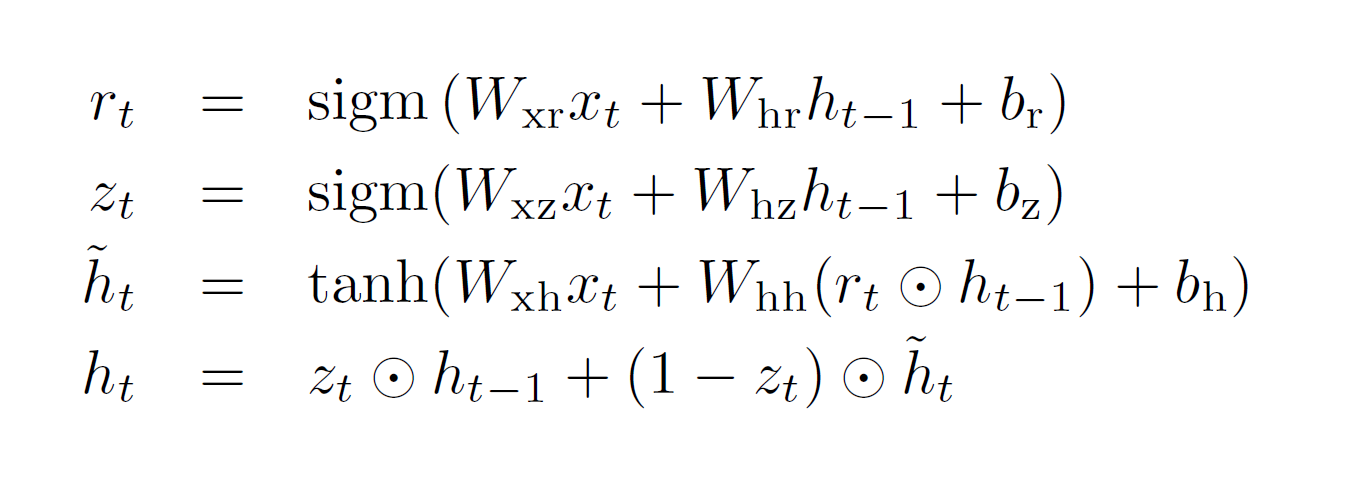
Fig. 5.2f. GRU formula, p. 3, [28].
-----

Fig. 5.3a. Gated Feedback RNN, p. 4, [29].
-----

Fig. 5.3b. Structure of IMAGINET, p. 2, [30].
-----
結論:
圖5.1a 是本篇文章的核心。由於省略不少符號,以及流程的重複,並不容易瞭解。所以我認為還是要反覆搭配公式才能有較通透的理解。
本文只有講解 LSTM 與 GRU 的架構。有關輸入的文字向量部分,若有時間再補充。
-----
出版說明:
2019/10/21
跟 CNN 相比,RNN(LSTM、GRU) 是比較難理解的概念,特別是 LSTM 裡面的幾個門。不過,你可以把 LSTM 想成沒有卷積,然後順時針方向旋轉九十度的 CNN,也許這樣比較容易理解,因為一般深度學習是從圖像處理的 CNN 開始。
除了音訊之外,RNN 較早時也用來處理自然語言。有人問,目前 NLP 轉進 self attention,那還要不要學 LSTM。答案是肯定的,因為 LSTM 只是基礎而已。事實上,LSTM 的一些概念如 identity mapping(skip connection)被用在 ResNet,而 gate 也被用在稍後的 ConvS2S。
-----
References
◎ 1 Intro
[1] 100_rnn
http://www.deeplearningbook.org/contents/rnn.html
[2] 2016_Towards Bayesian Deep Learning, A Survey
◎ 1 Intro Internet
[3] 淺談Deep Learning原理及應用
http://www.cc.ntu.edu.tw/chinese/epaper/0038/20160920_3805.html
[4] A Beginner's Guide to Recurrent Networks and LSTMs - Deeplearning4j Open-source, Distributed Deep Learning for the JVM
https://deeplearning4j.org/lstm
[5] All of Recurrent Neural Networks – Medium_m4c8pmg3d
https://medium.com/@jianqiangma/all-about-recurrent-neural-networks-9e5ae2936f6e
[6] Recurrent Layers - Keras Documentation
https://keras.io/layers/recurrent/
[7] Recurrent Layers - TFLearn
http://tflearn.org/layers/recurrent/
[8] Recurrent Neural Networks in Tensorflow II - R2RT
http://r2rt.com/recurrent-neural-networks-in-tensorflow-ii.html
◎ 2 RNN
[9] 2011_Generating Text with Recurrent Neural Networks
[10] 2013_How to construct deep recurrent neural networks
2 RNN Internet
[11] Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs – WildML
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
[12] Recurrent Neural Networks Tutorial, Part 2 – Implementing a RNN with Python, Numpy and Theano – WildML
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-2-implementing-a-language-model-rnn-with-python-numpy-and-theano/
◎ 3 BPTT
[13] 1990_Backpropagation through time, what it does and how to do it
[14] 2015_Automatic speech recognition, a deep learning approach_237-266
◎ 3 BPTT Internet
[15] AI從頭學(九):Back Propagation
http://hemingwang.blogspot.tw/2017/02/aiback-propagation.html
[16]
[17] Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradients – WildML
http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/
◎ 4 LSTM
[18] 1997_Long short-term memory
[19] 2000_Learning to forget, Continual prediction with LSTM
[20] 2002_Learning precise timing with LSTM recurrent networks
[21] 2012_Supervised Sequence Labelling with Recurrent Neural Networks_37-45
[22] 2013_Hybrid speech recognition with deep bidirectional LSTM
[23] 2016_LSTM, A search space odyssey
◎ 4 LSTM Internet
[24] Optimizing Recurrent Neural Networks in cuDNN 5
https://devblogs.nvidia.com/parallelforall/optimizing-recurrent-neural-networks-cudnn-5/
[25] Recurrent Neural Network Configuration — PaddlePaddle documentation
http://www.paddlepaddle.org/doc/algorithm/rnn/rnn.html
[26] Understanding LSTM Networks -- colah's blog
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
◎ 5 GRU
[27] 2014_Empirical evaluation of gated recurrent neural networks on sequence modeling
[28] 2015_An empirical evaluation of recurrent network architectures
[29] 2015_Gated feedback recurrent neural networks
[30] 2015_Learning language through pictures
◎ 5 GRU Internet
[31] chainer_links_connection_gru — Chainer 1_22_0 documentation
http://docs.chainer.org/en/latest/_modules/chainer/links/connection/gru.html
[32] theanets_layers_recurrent_GRU — Theanets 0_7_3 documentation
http://theanets.readthedocs.io/en/stable/api/generated/theanets.layers.recurrent.GRU.html
[33] Recurrent Neural Network Tutorial, Part 4 – Implementing a GRU-LSTM RNN with Python and Theano – WildML
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano/
[34] LSTM与GRU的一些比较--论文笔记 - meanme的专栏 - 博客频道 - CSDN_NET
http://blog.csdn.net/meanme/article/details/48845793
[35] Review - Gated Recurrent Units Prof_Xuechen's Personal Blog
https://professorstudio.github.io/2016/08/01/gru/
[36] 机器之心 LSTM和递归网络基础教程
http://www.jiqizhixin.com/article/1364
[37] 深度学习与层级性:从RNN到注意力与记忆 张江
http://www.twoeggz.com/news/3988531.html
-----
補充資料:
[38] 有哪些LSTM(Long Short Term Memory)和RNN(Recurrent)网络的教程?
https://www.zhihu.com/question/29411132
[39] 零基础入门深度学习(6) - 长短时记忆网络(LSTM)
https://zybuluo.com/hanbingtao/note/581764?from=groupmessage
No comments:
Post a Comment