2020/09/10
-----
說明:
AlexNet 論文中有提到 Weight Decay 與 Momentum,初學者一般會忽略。VGGNet 論文中一樣有提到 Weight Decay 與 Momentum,讀到 VGGNet 時,基本上已經不算初學者,所以不應該忽略。
總之,Regularization 與 Optimization 是深度學習兩大主題,Deep Learning Book 也分別有兩章闡釋這兩個主題,可見它們的重要性。
在準備 Weight Decay 的過程中,找到《A disciplined approach to neural network hyper-parameters: Part 1--learning rate, batch size, momentum, and weight decay.》這篇論文,裡面討論 Dataset、Model。以及四個重要的超參數:Learning Rate(CLR、1cycle/super-convergence)、Batch Size、Momentum、Weight Decay。
動手訓練模型的工程師,可以仔細讀一下這篇論文。
-----

https://pixabay.com/zh/photos/parameter-flight-water-sunset-rays-4697544/
註解一:超參數。
-----
「論文的主要貢獻:
1. 提出幾種找最優超參的方法論。2. test 的 loss 也很重要,不能只看 test 的準確率。3. 增加學習率有助於減少欠擬合,學習率太小可能會表現出一些過擬合的行為。大的學習率有正則化效果,但過大的 LR 又會導致訓練不能收斂。4. 大學習率有兩個好處,一有正則化效應可以避免過擬合,二是可以更快的訓練。5. 在增加學習率的同時減小動量。6. 因為更大的學習率有正則化效應,所以用更小的權重衰減更合適。」[8]。
-----
「讀後感:
信息密度還是非常高的一篇,讀起來沒那麼容易。簡直就是神文,堪稱實驗設計指導手冊,各種玄學調參。此外本文給人的感覺是缺少一些理論依據,更多的是通過各種實驗對比得出結論的。深度學習中這個事後找理論問題太明顯了,本文算是其中的典範。最後,全部讀完後,發現 tricks 並沒有之前預期那麼多,主要內容就是 CLR 和 super convergence 的內容。」[8]。
-----

Fig. Cyclical learning rates [2], [6]。
註解二、CLR,週期學習率。['saiklikl]。
-----

Fig. Super-convergence [3], [6]。
註解三:1cycle、Super-convergence。學習率由小到大,再由大到小。可搭配週期動量。
-----

Fig. 重點整理 [4]。
註解四:Table of LR、BS、Momentum、Weight Decay。
大的學習率可以增加正則化、加速收斂,缺點是不穩定,可能無法收斂。小的學習率主要容易導致過擬合。
大的批次量有較少的正則化。小的批次量有較大的正則化。
動量要配合學習率。
大的權重衰減值增加正則化。小的值正則化程度較低。
-----
Fig. Highlights [1]。
註解五:重點在哪裡?圖表、Remark、Checklist。
Since this report is long, the reader who only wants the highlights of this report can: (1) look at every Figure and caption, (2) read the paragraphs that start with Remark, and (2) review the hyperparameter checklist at the beginning of Section 5.
由於報告很長,只求重點的讀者可以:(1)查看每張圖片及其說明,(2)閱讀以 Remark 開頭的段落,以及(2)查看第 5 節開頭的超參數清單。
-----

Fig. Checklist1. Learning rate [1]。
Learning rate (LR): Perform a learning rate range test to a “large” learning rate. The max LR depends on the architecture (for the shallow 3-layer architecture, large is 0.01 while for resnet, large is 3.0), you might try more than one maximum. Using the 1cycle LR policy with a maximum learning rate determined from an LR range test, a minimum learning rate as a tenth of the maximum appears to work well but other factors are relevant, such as the rate of learning rate increase (too fast and increase will cause instabilities).
學習率(LR):對「大」學習率進行學習率範圍測試。 最大 LR 取決於架構(對於淺層 3 層架構,大為 0.01,而對於 ResNet,大為 3.0),您可以嘗試多個最大值。使用 1cycle LR 策略
根據 LR 範圍測試確定的最大學習率,最小學習率為最大值的十分之一,因為看起來效果很好,但其他因素也很重要,例如提高學習率(會導致不穩定)。
註解六:C1、LR。
淺的網路的大學習率可能為 0.01。深的網路如 ResNet,大學習率可能為 3。最小值可能是最大值的 1/10。
-----

Fig. Checklist2. Total batch size [1]。
Total batch size (TBS): A large batch size works well but the magnitude is typically constrained by the GPU memory. If your server has multiple GPUs, the total batch size is the batch size on a GPU multiplied by the number of GPUs. If the architecture is small or your hardware permits very large batch sizes, then you might compare performance of different batch sizes. In addition, recall that small batch sizes add regularization while large batch sizes add less, so utilize this while balancing the proper amount of regularization. It is often better to use a larger batch size so a larger learning rate can be used.
總批次量(TBS):較大的批次量,效果很好,但常受到 GPU 記憶體的限制。 如果您的伺服器有多個 GPU,則總批大小為 GPU 的批量大小乘以 GPU 的數量。 如果架構很小或您的硬體允許非常大的批量,那麼您可以比較不同型號的性能批次大小。 另外,注意,小批量時增加了正則化,而大批量時正則化影響較小,因此請在平衡適當數量的正則化時利用它。最好使用較大的批量,以便可以使用較大的學習率。
註解七:C2、BS。
記憶體許可以話,儘量使用大批次量。對正則化有幫助,也可以使用大學習率,也比較快。
小值正則化多、大值正則化少。大值可配合大 LR。
-----

Fig. Checklist3. Momentum [1]。
-----

Fig. Checklist3. Momentum [1]。
Momentum: Short runs with momentum values of 0.99, 0.97, 0.95, and 0.9 will quickly show the best value for momentum. If using the 1cycle learning rate schedule, it is better to use a cyclical momentum (CM) that starts at this maximum momentum value and decreases with increasing learning rate to a value of 0.8 or 0.85 (performance is almost independent of the minimum momentum value). Using cyclical momentum along with the LR range test stabilizes the convergence when using large learning rate values more than a constant momentum does.
註解八:C3、Momentum。
上面的英文跟 Google 翻譯都很奇怪。
摘錄重點:先快速測試一下最大動量。然後使用 1cycle 策略,學習率從小到大再到小,搭配的週期動量則在 0.9 與 0.8 之間震盪(舉例來說)。
很快先找一個。1cycle 配合週期動量。
-----

Fig. Checklist4. Weight decay [1]。
-----

Fig. Checklist4. Weight decay [1]。
Weight decay (WD): This requires a grid search to determine the proper magnitude but usually does not require more than one significant figure accuracy. Use your knowledge of the dataset and architecture to decide which values to test. For example, a more complex dataset requires less regularization so test smaller weight decay values, such as 104; 105; 106; 0. A shallow architecture requires more regularization so test larger weight decay values, such as 102; 103; 104.
權重衰減(WD):這需要進行網格搜索以確定合適的幅度,但通常不需要一個以上的有效數字精度。 根據你對數據集和模型架構的瞭解,確定要測試的值。 例如,較複雜的數據集需要較少的正則化,因此可以測試較小的權重衰減值,例如10^-4; 10^-5; 10^-6; 0。淺的架構需要更多正則化,因此測試更大權重衰減值,例如10^-2; 10^-3; 10^-4。
註解九:C4、Weight Decay。
權重衰減的值,要根據數據集與模型複雜度設定。複雜的數據集不用太多正則化。簡單的架構需要較多正則化。
複雜資料集用小 WD,小模型用大 WD。
-----

Fig. 1. Comparison of the training loss, validation accuracy, generalization error [1]。
-----

Fig. 1. Comparison of the training loss, validation accuracy, generalization error [1]。
Figure 1: Comparison of the training loss, validation accuracy, validation loss, and generalization error that illustrates the additional information about the training process in the test/validation loss but is not visible in the test accuracy and training loss or clear with the generalization error. These runs are a learning rate range test with the resnet-56 architecture and Cifar-10 dataset.
圖1:訓練損失,驗證準確性,驗證損失和概括性的比較錯誤,說明有關測試/驗證損失中的訓練過程的其他信息,但是在測試準確性和訓練損失上看不到,也看不到泛化誤差。 這些運行使用 ResNet-56 和 Cifar-10 數據集的學習率範圍測試。
註解十:F1。generalization error,泛化誤差(測試集或新樣本的誤差,非訓練集的誤差)。
-----
Fig. Remark 1 [1]。
The test/validation loss is a good indicator of the network’s convergence and should be examined for clues. In this report, the test/validation loss is used to provide insights on the training process and the final test accuracy is used for comparing performance.
測試/驗證損失是網路收斂的一個很好的指標,檢查以便找到線索。在此報告中,測試/驗證損失用於提供有關訓練過程的訣竅和最終用於比較性能的測試精度。
簡單說,先從 test/validation 的損失中找調整超參數的線索。
註解十一:R1。照念。
-----

Fig. 2. Overfitting and Underfitting [1]。
Figure 2: Pictorial explanation of the tradeoff between underfitting and overfitting. Model complexity (the x axis) refers to the capacity or powerfulness of the machine learning model. The figure shows the optimal capacity that falls between underfitting and overfitting.
圖2:欠擬合和過擬合之間折衷的圖形說明。 模型複雜度(x軸)指的是機器學習模型的能力。 該圖顯示介於欠擬合和過擬合之間的最佳容量。
註解十二:F2。Underfitting and Overfitting。註解十四與十五是註解十二的補充。
-----

Fig. Remark 2 [1]。
The takeaway is that achieving the horizontal part of the test loss is the goal of hyperparameter tuning. Achieving this balance can be difficult with deep neural networks. Deep networks are very powerful, with networks becoming more powerful with greater depth (i.e., more layers), width (i.e, more neurons or filters per layer), and the addition of skip connections to the architecture. Also, there are various forms of regulation, such as weight decay or dropout (Srivastava et al., 2014). One needs to vary important hyper-parameters and can use a variety of optimization methods, such as Nesterov or Adam (Kingma & Ba, 2014). It is well known that optimizing all of these elements to achieve the best performance on a given dataset is a challenge.
得出的結論是,實現測試損失的水平部分(收斂)是調整超參數的目標。 深度神經網路很難實現這種平衡。 深度網路功能非常強大,網路隨著深度(例如,更多層)變得越來越強大,
寬度(即每層更多的神經元或濾波器),以及添加直通架構。此外,還有各種形式的調節,例如權重衰減或 dropout(Srivastava等,2014)。我們需要更改重要的超參數,並且可以使用多種優化方法,例如 Nesterov 或 Adam(Kingma&Ba,2014)。 眾所周知,優化所有這些元素在給定的數據集上實現最佳性能是一個挑戰。
簡單說,各種方法都要知道(這是廢話)。
-----

Fig. Remark 2 [1]。
The takeaway is that achieving the horizontal part of the test loss is the goal of hyperparameter tuning. Achieving this balance can be difficult with deep neural networks. Deep networks are very powerful, with networks becoming more powerful with greater depth (i.e., more layers), width (i.e, more neurons or filters per layer), and the addition of skip connections to the architecture. Also, there are various forms of regulation, such as weight decay or dropout (Srivastava et al., 2014). One needs to vary important hyper-parameters and can use a variety of optimization methods, such as Nesterov or Adam (Kingma & Ba, 2014). It is well known that optimizing all of these elements to achieve the best performance on a given dataset is a challenge.
得出的結論是,實現測試損失的水平部分(收斂)是調整超參數的目標。 深度神經網路很難實現這種平衡。 深度網路功能非常強大,網路隨著深度(例如,更多層)變得越來越強大,
寬度(即每層更多的神經元或濾波器),以及添加直通架構。此外,還有各種形式的調節,例如權重衰減或 dropout(Srivastava等,2014)。我們需要更改重要的超參數,並且可以使用多種優化方法,例如 Nesterov 或 Adam(Kingma&Ba,2014)。 眾所周知,優化所有這些元素在給定的數據集上實現最佳性能是一個挑戰。
簡單說,各種方法都要知道(這是廢話)。
註解十三:R2。廢話。
-----

Fig. 3. 小資料集對小網路,大資料集對大網路。Test loss [1]。
Figure 3: Underfitting is characterized by a continuously decreasing test loss, rather than a horizontal plateau. Underfitting is visible during the training on two different datasets, Cifar-10 and imagenet.
圖3:欠擬合的特徵是測試損失不斷降低,而不是水平降低的高原。 在訓練過程中,可以在兩個不同的數據集 Cifar-10 和 imagenet 上看到擬合不足。
註解十四:F3。Underfitting 是 test loss 一直下降。註解十四與十五是註解十二的補充。
-----

Fig. 4. 小資料集對小網路,大資料集對大網路 [1]。
Figure 4: Increasing validation/test loss indicates overfitting. Examples of overfitting are shown for Cifar-10 and Imagenet. WD = weight decay, LR = learning rate, CLR = cyclical learning rate, CM = cyclical momentum.
圖4:增加的驗證/測試損失意味著過度擬合。Cifar-10 和 Imagenet 上的過擬合例子。 WD = 權重衰減,LR = 學習率,CLR = 週期學習率,CM = 週期動量。
-----

Fig. 3. 小資料集對小網路,大資料集對大網路。Test loss [1]。
Figure 3: Underfitting is characterized by a continuously decreasing test loss, rather than a horizontal plateau. Underfitting is visible during the training on two different datasets, Cifar-10 and imagenet.
圖3:欠擬合的特徵是測試損失不斷降低,而不是水平降低的高原。 在訓練過程中,可以在兩個不同的數據集 Cifar-10 和 imagenet 上看到擬合不足。
註解十四:F3。Underfitting 是 test loss 一直下降。註解十四與十五是註解十二的補充。
-----

Fig. 4. 小資料集對小網路,大資料集對大網路 [1]。
Figure 4: Increasing validation/test loss indicates overfitting. Examples of overfitting are shown for Cifar-10 and Imagenet. WD = weight decay, LR = learning rate, CLR = cyclical learning rate, CM = cyclical momentum.
圖4:增加的驗證/測試損失意味著過度擬合。Cifar-10 和 Imagenet 上的過擬合例子。 WD = 權重衰減,LR = 學習率,CLR = 週期學習率,CM = 週期動量。
註解十五:Overfitting 是 validation / test loss一職上升。註解十四與十五是註解十二的補充。
-----

Fig. 5. Super-convergence and WD。
Figure 5: Faster training is possible by allowing the learning rates to become large. Other regularization methods must be reduced to compensate for the regularization effects of large learning rates. Practitioners must strive for an optimal balance of regularization.
圖5:藉著加大學習率,可以加快訓練。其他正則化方法則必須降低,以補償加大學習率產生的正則化效應。學習者必須努力實現正則化的最佳平衡。
-----

Fig. 5. Super-convergence and WD。
Figure 5: Faster training is possible by allowing the learning rates to become large. Other regularization methods must be reduced to compensate for the regularization effects of large learning rates. Practitioners must strive for an optimal balance of regularization.
圖5:藉著加大學習率,可以加快訓練。其他正則化方法則必須降低,以補償加大學習率產生的正則化效應。學習者必須努力實現正則化的最佳平衡。
註解十六:F5。strive means try very hard。
-----

Fig. Remark 3 [1]。
A general principle is: the amount of regularization must be balanced for each dataset and architecture. Recognition of this principle permits general use of super-convergence. Reducing other forms of regularization and regularizing with very large learning rates makes training significantly more efficient.
一般原則是:正則化量必須數據集和模型之間保持平衡。認識到該原理後,則可以使用超收斂。 減少其他形式的正則化和使用高學習率能使訓練效果更顯著。
簡單說,要先知道各種超參數的特性,然後用超收斂。
-----
Fig. Remark 3 [1]。
A general principle is: the amount of regularization must be balanced for each dataset and architecture. Recognition of this principle permits general use of super-convergence. Reducing other forms of regularization and regularizing with very large learning rates makes training significantly more efficient.
一般原則是:正則化量必須數據集和模型之間保持平衡。認識到該原理後,則可以使用超收斂。 減少其他形式的正則化和使用高學習率能使訓練效果更顯著。
簡單說,要先知道各種超參數的特性,然後用超收斂。
註解十七:R3。1cycle 是大的 LR 加上其他小的 regularization。註解十七是註解十六的補充。
-----

Fig. 6. TBS vs test accuracy and loss [1]。
Figure 6: The effects of total batch size (TBS) on validation accuracy/loss for the Cifar-10 with resnet-56 and a 1cycle learning rate schedule. For a fixed computational budget, larger TBS yields higher test accuracy but smaller TBS has lower test loss.
圖6:在 Cifar-10 上,對 ResNet-56,用 1-cycle,評估 TBS,對對驗證準確性/損失的影響。
-----

Fig. 6. TBS vs test accuracy and loss [1]。
Figure 6: The effects of total batch size (TBS) on validation accuracy/loss for the Cifar-10 with resnet-56 and a 1cycle learning rate schedule. For a fixed computational budget, larger TBS yields higher test accuracy but smaller TBS has lower test loss.
圖6:在 Cifar-10 上,對 ResNet-56,用 1-cycle,評估 TBS,對對驗證準確性/損失的影響。
對於固定的運算力,較大的 TBS 產生較大的測試精度,但較小的 TBS 測試損失較低。
註解十八:F6。BS on test accuracy / loss。
-----

Fig. Remark 4 [1]。
The takeaway message of this Section is that the practitioner’s goal is obtaining the highest performance while minimizing the needed computational time. Unlike the learning rate hyper-parameter where its value doesn’t affect computational time, batch size must be examined in conjunction with the execution time of the training. Similarly, choosing the number of epochs/iterations for training should be large enough to maximize the final test performance but no larger.
本節的重點是,練習者的目標是獲得最高的性能,同時大大減少所需的計算時間。 與學習率
超參數(其值不影響計算時間)不同,批次大小必須同時考慮訓練的執行時間。 同樣,選擇時期/迭代次數,訓練時期的大小應該足夠大,盡可能提高最終測試性能,但也不能太大。
簡單說,BS 儘量大一點。
-----
Fig. Remark 4 [1]。
The takeaway message of this Section is that the practitioner’s goal is obtaining the highest performance while minimizing the needed computational time. Unlike the learning rate hyper-parameter where its value doesn’t affect computational time, batch size must be examined in conjunction with the execution time of the training. Similarly, choosing the number of epochs/iterations for training should be large enough to maximize the final test performance but no larger.
本節的重點是,練習者的目標是獲得最高的性能,同時大大減少所需的計算時間。 與學習率
超參數(其值不影響計算時間)不同,批次大小必須同時考慮訓練的執行時間。 同樣,選擇時期/迭代次數,訓練時期的大小應該足夠大,盡可能提高最終測試性能,但也不能太大。
簡單說,BS 儘量大一點。
註解十九:R4。BS 跟時間關係很大,儘可能大一點。
-----

Fig. 7. Cyclical momentum and Cifar-10 and a shallow 3 layer network [1]。
Figure 7: Cyclical momentum tests for the Cifar-10 dataset with a shallow 3 layer network.
圖7:在 Cifar-10 數據集上,對三層的淺層網路,進行循環動量測試。
(a) Showing that the value of momentum matters.
(a)表明動量影響結果很大。
(b) Increasing momentum does not find an optimal value.
(b)增加動量不一定讓結果變好。
(c) Cyclical momentum combined with cyclical learning rates.
(c)週期動量與週期學習率相結合。
(d) Comparing using a constant momentum to cyclical momentum.
(d)比較固定動量與週期動量。
-----

Fig. 7. Cyclical momentum and Cifar-10 and a shallow 3 layer network [1]。
Figure 7: Cyclical momentum tests for the Cifar-10 dataset with a shallow 3 layer network.
圖7:在 Cifar-10 數據集上,對三層的淺層網路,進行循環動量測試。
(a) Showing that the value of momentum matters.
(a)表明動量影響結果很大。
(b) Increasing momentum does not find an optimal value.
(b)增加動量不一定讓結果變好。
(c) Cyclical momentum combined with cyclical learning rates.
(c)週期動量與週期學習率相結合。
(d) Comparing using a constant momentum to cyclical momentum.
(d)比較固定動量與週期動量。
註解二十:F7。順序算是清楚。
-----

Fig. Remark 5 [1]。
The main point of this Section is that optimal momentum value(s) will improve network training. As demonstrated below, the optimal training procedure is a combination of an increasing cyclical learning rate, where an initial small learning rate permits convergence to begin, and a decreasing cyclical momentum, where the decreasing momentum allows the learning rate to become larger in the early to middle parts of training. However, if a constant learning rate is used then a large constant momentum (i.e., 0.9-0.99) will act like a pseudo increasing learning rate and will speed up the training. However, use of too large a value for momentum causes poor training results that are visible early in the training and this can be quickly tested.
本節的要點是,最佳動量值將改善網路的訓練。 如下所示,最佳訓練過程是漸增的
週期性學習率,與漸減的週期動量。初始的小學習率可以讓收斂開始進行。遞減的動量可以讓早期與中期的學習率大一點。無論如何,如果使用恆定的學習率,那麼恆定的動量(即 0.9-0.99)會像偽增加的學習率一樣起作用並且會加快訓練。 但是,使用過大的動量值會導致在訓練的早期就可見到不佳的訓練結果,這可以很快測試到。
簡單說,momentum 用來搭配 LR。
-----

Fig. Remark 5 [1]。
The main point of this Section is that optimal momentum value(s) will improve network training. As demonstrated below, the optimal training procedure is a combination of an increasing cyclical learning rate, where an initial small learning rate permits convergence to begin, and a decreasing cyclical momentum, where the decreasing momentum allows the learning rate to become larger in the early to middle parts of training. However, if a constant learning rate is used then a large constant momentum (i.e., 0.9-0.99) will act like a pseudo increasing learning rate and will speed up the training. However, use of too large a value for momentum causes poor training results that are visible early in the training and this can be quickly tested.
本節的要點是,最佳動量值將改善網路的訓練。 如下所示,最佳訓練過程是漸增的
週期性學習率,與漸減的週期動量。初始的小學習率可以讓收斂開始進行。遞減的動量可以讓早期與中期的學習率大一點。無論如何,如果使用恆定的學習率,那麼恆定的動量(即 0.9-0.99)會像偽增加的學習率一樣起作用並且會加快訓練。 但是,使用過大的動量值會導致在訓練的早期就可見到不佳的訓練結果,這可以很快測試到。
簡單說,momentum 用來搭配 LR。
註解二一:R5。策略是增加的週期 LR 與降低的週期動量。
-----

Fig. Table 1 [1]。
Table 1: Cyclical momentum tests; final accuracy and standard deviation for the Cifar-10 dataset with various architectures. For deep architectures, such as resnet-56, combining cyclical learning and cyclical momentum is best, while for shallow architectures optimal constant values work as well as cyclical ones. SS = stepsize, where two steps in a cycle in epochs, WD = weight decay.
表1:循環動量測試; 各種架構上,Cifar-10 數據集的最終精度和標準差。對較深的網路,例如 ResNet-56,結合週期學習率和周期動量,表現最佳。對於淺的網路,找個最佳常數也不錯。 SS = 步長,其中一個週期中有兩個步長,WD = 權重衰減。
-----

Fig. Table 1 [1]。
Table 1: Cyclical momentum tests; final accuracy and standard deviation for the Cifar-10 dataset with various architectures. For deep architectures, such as resnet-56, combining cyclical learning and cyclical momentum is best, while for shallow architectures optimal constant values work as well as cyclical ones. SS = stepsize, where two steps in a cycle in epochs, WD = weight decay.
表1:循環動量測試; 各種架構上,Cifar-10 數據集的最終精度和標準差。對較深的網路,例如 ResNet-56,結合週期學習率和周期動量,表現最佳。對於淺的網路,找個最佳常數也不錯。 SS = 步長,其中一個週期中有兩個步長,WD = 權重衰減。
註解二二:T1。各種組合。2000 個樣本。BS 500,完成一個 epoch 需要 4 個 iteration。
-----

Fig. 8. Constant and cyclical momentum [1]。
Figure 8: Examples of the cyclical momentum with the Cifar-10 dataset and resnet-56. The best result is when momentum decreases as learning rate increases.
圖8:使用 Cifar-10 數據集,在 ResNet-56 的周期動量的例子。 最好的結果是動量隨著學習率的提高而降低。
-----

Fig. 8. Constant and cyclical momentum [1]。
Figure 8: Examples of the cyclical momentum with the Cifar-10 dataset and resnet-56. The best result is when momentum decreases as learning rate increases.
圖8:使用 Cifar-10 數據集,在 ResNet-56 的周期動量的例子。 最好的結果是動量隨著學習率的提高而降低。
註解二三:F8。原本以為 (b) 應該是 CLR。其實內容並沒有問題。
-----

Fig. 9. WD by test loss and by test accuracy [1]。
Figure 9: Examples of weight decay search using a 3-layer network on the Cifar-10 dataset. Training used a constant learning rate (0.005) and constant momentum (0.95). The best value for weight decay is easier to interpret from the loss than from the accuracy.
圖9:在 Cifar-10 數據集上,對 3 層網路,進行權重衰減搜索的例子。 訓練使用了固定學習率(0.005)和固定動量(0.95)。用損失比用精度容易闡釋最佳 WD。

Fig. 9. WD by test loss and by test accuracy [1]。
Figure 9: Examples of weight decay search using a 3-layer network on the Cifar-10 dataset. Training used a constant learning rate (0.005) and constant momentum (0.95). The best value for weight decay is easier to interpret from the loss than from the accuracy.
圖9:在 Cifar-10 數據集上,對 3 層網路,進行權重衰減搜索的例子。 訓練使用了固定學習率(0.005)和固定動量(0.95)。用損失比用精度容易闡釋最佳 WD。
註解二四:F9。WD search,(a) 比 (b) 容易找。
-----

Fig. Remark 6 [1]。
Since the amount of regularization must be balanced for each dataset and architecture, the value of weight decay is a key knob to turn for tuning regularization against the regularization from an increasing learning rate. While other forms of regularization are generally fixed (i.e., dropout ratio, stochastic depth), one can easily change the weight decay value when experimenting with maximum learning rate and stepsize values.
由於必須針對每個數據集和模型架構平衡正則化的量,所以在漸增的學習率中,可以改變權重衰減的值以調節正則化。雖然其他形式的正則化通常是固定的(即,dropout ratio,ResNet 的 stochastic depth),但我們可以在具有最大的學習率和逐步調整值的實驗時輕易更改權重衰減值。
簡單說,WD 比較彈性。
Fig. Remark 6 [1]。
Since the amount of regularization must be balanced for each dataset and architecture, the value of weight decay is a key knob to turn for tuning regularization against the regularization from an increasing learning rate. While other forms of regularization are generally fixed (i.e., dropout ratio, stochastic depth), one can easily change the weight decay value when experimenting with maximum learning rate and stepsize values.
由於必須針對每個數據集和模型架構平衡正則化的量,所以在漸增的學習率中,可以改變權重衰減的值以調節正則化。雖然其他形式的正則化通常是固定的(即,dropout ratio,ResNet 的 stochastic depth),但我們可以在具有最大的學習率和逐步調整值的實驗時輕易更改權重衰減值。
簡單說,WD 比較彈性。
註解二五:R6。WD 容易改變值去調整。
-----
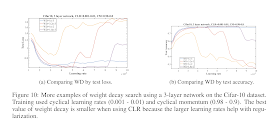
Fig. 10. WD by test loss and by test accuracy [1]。
Figure 10: More examples of weight decay search using a 3-layer network on the Cifar-10 dataset. Training used cyclical learning rates (0.001 - 0.01) and cyclical momentum (0.98 - 0.9). The best value of weight decay is smaller when using CLR because the larger learning rates help with egularization.
圖10:在 Cifar-10 數據集上,對 3 層網路,進行權重衰減搜索的更多例子。訓練使用周期學習率(0.001-0.01)和周期動量(0.98-0.9)。 使用 CLR 時,最佳權重衰減的值較小,因為較大的學習率有助於正則化。
-----

Fig. 11. Constant learning rate (=0.1) and Learning rate range (=0.1-1) [1]。
Figure 11: Grid search for weight decay (WD) on Cifar-10 with resnet-56 and a constant momentum = 0.95 and TBS = 1,030. The optimal weight decay is different if you search with a constant learning rate (left) versus using a learning rate range (right) due to the regularization by large learning
rates.
圖11:在 Cifar-10 上,用 0.95 的固定動量,與 1030 的 TBS,對 ResNet-56 進行 WD 的網格搜尋。由於大學習率的正則化有所不同,用固定 LR(左)與與使用學習率範圍(右)的最佳 WD 也會不一樣。
-----

Fig. 12. Cifar-10, 3-layer network & Resnet-56, WD [1]。
Figure 12: Grid search for the optimal WD restarting from a snapshot. These results on Cifar-10 indicate that a grid search from a snapshot will point to an optimal weight decay and can save time.
圖12:最佳 WD 的網格搜索快照。 Cifar-10上的這些結果表示從快照進行網格搜索將指向最佳權重衰減並可以節省時間。
-----

Fig. 10. WD by test loss and by test accuracy [1]。
Figure 10: More examples of weight decay search using a 3-layer network on the Cifar-10 dataset. Training used cyclical learning rates (0.001 - 0.01) and cyclical momentum (0.98 - 0.9). The best value of weight decay is smaller when using CLR because the larger learning rates help with egularization.
圖10:在 Cifar-10 數據集上,對 3 層網路,進行權重衰減搜索的更多例子。訓練使用周期學習率(0.001-0.01)和周期動量(0.98-0.9)。 使用 CLR 時,最佳權重衰減的值較小,因為較大的學習率有助於正則化。
註解二六:F10。LR 大,WD 則小。
-----

Fig. 11. Constant learning rate (=0.1) and Learning rate range (=0.1-1) [1]。
Figure 11: Grid search for weight decay (WD) on Cifar-10 with resnet-56 and a constant momentum = 0.95 and TBS = 1,030. The optimal weight decay is different if you search with a constant learning rate (left) versus using a learning rate range (right) due to the regularization by large learning
rates.
圖11:在 Cifar-10 上,用 0.95 的固定動量,與 1030 的 TBS,對 ResNet-56 進行 WD 的網格搜尋。由於大學習率的正則化有所不同,用固定 LR(左)與與使用學習率範圍(右)的最佳 WD 也會不一樣。
註解二七:F11。在不同的 LR 條件找最佳 WD。
-----

Fig. 12. Cifar-10, 3-layer network & Resnet-56, WD [1]。
Figure 12: Grid search for the optimal WD restarting from a snapshot. These results on Cifar-10 indicate that a grid search from a snapshot will point to an optimal weight decay and can save time.
圖12:最佳 WD 的網格搜索快照。 Cifar-10上的這些結果表示從快照進行網格搜索將指向最佳權重衰減並可以節省時間。
註解二八:F12。同 F11。
-----

Fig. 13. WD-WRN, Momentum-DenseNet, WD-DenseNet, TBS-DenseNet [1]。
Figure 13: Illustration of hyper-parameter search for wide resnet and densenet on Cifar-10. Training follows the learning rate range test of (LR=0.1 – 1) for widenet and (LR=0.1 – 4) for densenet, and cycling momentum (=0.95 – 0.85). For the densenet architecture, the test accuracy is easier to interpret for the best weight decay (WD) than the test loss.
圖13:在 Cifar-10上針對 WRN 與 DenseNet 的超參數搜索。 訓練遵循針對 WRN 的(LR = 0.1 – 1)和針對 DenseNet 的(LR = 0.1 – 4)的學習率範圍測試,和循環動量(= 0.95 – 0.85)。 對於 DenseNet,用最佳 WD 闡釋測試精度比用測試損失解釋要容易的多。
-----

Fig. 13. WD-WRN, Momentum-DenseNet, WD-DenseNet, TBS-DenseNet [1]。
Figure 13: Illustration of hyper-parameter search for wide resnet and densenet on Cifar-10. Training follows the learning rate range test of (LR=0.1 – 1) for widenet and (LR=0.1 – 4) for densenet, and cycling momentum (=0.95 – 0.85). For the densenet architecture, the test accuracy is easier to interpret for the best weight decay (WD) than the test loss.
圖13:在 Cifar-10上針對 WRN 與 DenseNet 的超參數搜索。 訓練遵循針對 WRN 的(LR = 0.1 – 1)和針對 DenseNet 的(LR = 0.1 – 4)的學習率範圍測試,和循環動量(= 0.95 – 0.85)。 對於 DenseNet,用最佳 WD 闡釋測試精度比用測試損失解釋要容易的多。
註解二九:F13。WRN,DenseNet Momentum、WD、TBS。
-----

Fig. Table 2 [1]。
Table 2: Final accuracy and standard deviation for various datasets and architectures. The total batch size (TBS) for all of the reported runs was 512. PL = learning rate policy, SS = stepsize in epochs, here two steps are in a cycle, WD = weight decay, CM = cyclical momentum. Either SS or PL is provide in the Table and SS implies the cycle learning rate policy.
表2:各種數據集和模型架構的最終精度和標準差。 總批次大小(TBS)都是 512。PL = 學習率政策,SS = 歷時步長,其中兩個步驟是一個循環,WD = 權重衰減,CM = 週期性動量。 SS 或 PL是表中提供的 SS 表示週期學習率策略。

Fig. Table 2 [1]。
Table 2: Final accuracy and standard deviation for various datasets and architectures. The total batch size (TBS) for all of the reported runs was 512. PL = learning rate policy, SS = stepsize in epochs, here two steps are in a cycle, WD = weight decay, CM = cyclical momentum. Either SS or PL is provide in the Table and SS implies the cycle learning rate policy.
表2:各種數據集和模型架構的最終精度和標準差。 總批次大小(TBS)都是 512。PL = 學習率政策,SS = 歷時步長,其中兩個步驟是一個循環,WD = 權重衰減,CM = 週期性動量。 SS 或 PL是表中提供的 SS 表示週期學習率策略。
註解三十:T2。DenseNet 跟 LeNet 變化比較小。
-----

Fig. 14. Momentum and WD [1]。
Figure 14: Hyper-parameter search for MNIST dataset with a shallow, 3-layer network.
圖14:在三層的淺層網路上,對 MNIST 數據集進行超參數搜索。
-----

Fig. 14. Momentum and WD [1]。
Figure 14: Hyper-parameter search for MNIST dataset with a shallow, 3-layer network.
圖14:在三層的淺層網路上,對 MNIST 數據集進行超參數搜索。
註解三一:F14。清楚。
-----

Fig. 15. WD and TBS [1]。
Figure 15: Hyper-parameter search for the Cifar-100 dataset with the resnet-56 architecture.
圖15:在 resnet-56 上,對 Cifar-100 數據集進行超參數搜索。
-----

Fig. 15. WD and TBS [1]。
Figure 15: Hyper-parameter search for the Cifar-100 dataset with the resnet-56 architecture.
圖15:在 resnet-56 上,對 Cifar-100 數據集進行超參數搜索。
註解三二:F15。清楚。
-----

Fig. 16. ResNet vs Inception, 1cycle vs standard training LR [1]。
Figure 16: Training resnet and inception architectures on the imagenet dataset with the standard learning rate policy (blue curve) versus a 1cycle policy that displays super-convergence. llustrates that deep neural networks can be trained much faster (20 versus 100 epochs) than by using the standard training methods.
圖16:在 imagenet 數據集上訓練 ResNet 與 Inception 架構,使用標準方法(藍色曲線)與顯示超收斂的 1cycle 策略。圖片顯示 1cycle 比傳統方法快很多(20 vs 100 定型週期)。
-----
References
[1] Hyper-parameters
Smith, Leslie N. "A disciplined approach to neural network hyper-parameters: Part 1--learning rate, batch size, momentum, and weight decay." arXiv preprint arXiv:1803.09820 (2018).
https://arxiv.org/pdf/1803.09820.pdf
[2] Cyclical learning rates
Smith, Leslie N. "Cyclical learning rates for training neural networks." 2017 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2017.
https://arxiv.org/pdf/1506.01186.pdf
[3] Super-convergence
Smith, Leslie N., and Nicholay Topin. "Super-convergence: Very fast training of residual networks using large learning rates." (2018).
https://openreview.net/pdf?id=H1A5ztj3b
[4] Hyper-parameters tuning practices: learning rate, batch size, momentum, and weight decay. | by Sheng Fang | Analytics Vidhya | Medium
https://medium.com/analytics-vidhya/hyper-parameters-tuning-practices-learning-rate-batch-size-momentum-and-weight-decay-4b30f3c19ae8
[5] Finding Good Learning Rate and The One Cycle Policy. | by nachiket tanksale | Towards Data Science
https://towardsdatascience.com/finding-good-learning-rate-and-the-one-cycle-policy-7159fe1db5d6
[6] What’s up with Deep Learning optimizers since Adam? | by Phúc Lê | Vitalify Asia | Medium
https://medium.com/vitalify-asia/whats-up-with-deep-learning-optimizers-since-adam-5c1d862b9db0
[7] 1cycle策略:实践中的学习率设定应该是先增再降 | 机器之心
https://www.jiqizhixin.com/articles/041905
[8] 论文笔记 | ArXiv 2018 | A DISCIPLINED APPROACH TO NEURAL NETWORK HYPER-PARAMETERS: PART 1-DeepSmart.AI
http://www.deepsmart.ai/637.html
[9] 也来说说超参数 learning rate,weight decay和momentum - 知乎
https://zhuanlan.zhihu.com/p/48016051
[10] 【调参】Cyclic Learning Rates和One Cycle Policy-Keras_m0_37477175的博客-CSDN博客
https://blog.csdn.net/m0_37477175/article/details/89400436
[11] 第七十四篇:机器学习优化方法及超参数设置综述 - 曹明 - 博客园
https://www.cnblogs.com/think90/p/11610940.html
-----

Fig. 16. ResNet vs Inception, 1cycle vs standard training LR [1]。
Figure 16: Training resnet and inception architectures on the imagenet dataset with the standard learning rate policy (blue curve) versus a 1cycle policy that displays super-convergence. llustrates that deep neural networks can be trained much faster (20 versus 100 epochs) than by using the standard training methods.
圖16:在 imagenet 數據集上訓練 ResNet 與 Inception 架構,使用標準方法(藍色曲線)與顯示超收斂的 1cycle 策略。圖片顯示 1cycle 比傳統方法快很多(20 vs 100 定型週期)。
註解三三:F16。快速收斂。
-----
References
[1] Hyper-parameters
Smith, Leslie N. "A disciplined approach to neural network hyper-parameters: Part 1--learning rate, batch size, momentum, and weight decay." arXiv preprint arXiv:1803.09820 (2018).
https://arxiv.org/pdf/1803.09820.pdf
[2] Cyclical learning rates
Smith, Leslie N. "Cyclical learning rates for training neural networks." 2017 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2017.
https://arxiv.org/pdf/1506.01186.pdf
[3] Super-convergence
Smith, Leslie N., and Nicholay Topin. "Super-convergence: Very fast training of residual networks using large learning rates." (2018).
https://openreview.net/pdf?id=H1A5ztj3b
[4] Hyper-parameters tuning practices: learning rate, batch size, momentum, and weight decay. | by Sheng Fang | Analytics Vidhya | Medium
https://medium.com/analytics-vidhya/hyper-parameters-tuning-practices-learning-rate-batch-size-momentum-and-weight-decay-4b30f3c19ae8
[5] Finding Good Learning Rate and The One Cycle Policy. | by nachiket tanksale | Towards Data Science
https://towardsdatascience.com/finding-good-learning-rate-and-the-one-cycle-policy-7159fe1db5d6
[6] What’s up with Deep Learning optimizers since Adam? | by Phúc Lê | Vitalify Asia | Medium
https://medium.com/vitalify-asia/whats-up-with-deep-learning-optimizers-since-adam-5c1d862b9db0
[7] 1cycle策略:实践中的学习率设定应该是先增再降 | 机器之心
https://www.jiqizhixin.com/articles/041905
[8] 论文笔记 | ArXiv 2018 | A DISCIPLINED APPROACH TO NEURAL NETWORK HYPER-PARAMETERS: PART 1-DeepSmart.AI
http://www.deepsmart.ai/637.html
[9] 也来说说超参数 learning rate,weight decay和momentum - 知乎
https://zhuanlan.zhihu.com/p/48016051
[10] 【调参】Cyclic Learning Rates和One Cycle Policy-Keras_m0_37477175的博客-CSDN博客
https://blog.csdn.net/m0_37477175/article/details/89400436
[11] 第七十四篇:机器学习优化方法及超参数设置综述 - 曹明 - 博客园
https://www.cnblogs.com/think90/p/11610940.html
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.