Colab(八。三):Keras - Tutorials
2021/03/25
-----

https://pixabay.com/zh/photos/coyote-animal-wildlife-fox-snow-1730060/
-----
K01_Image classification from scratch(推薦:★★★★★ )
https://keras.io/examples/vision/image_classification_from_scratch/
2021/03/28
有兩種資料擴增的方法,第一種在 GPU,沒有成功。第二種在 CPU,懷疑不知是否因此變的很慢。原來 50 個 epochs,第一個跑完就重做。結果約 50 到 70 的正確率持續上升。重跑只設定 3 個 epochs。正確率一開始接近 0.5,跟亂猜差不多。
重新做一次,只用 2 個 epochs。正確率 0.76。結果把貓認成狗。貓 27.53。總之,實作算是成功。另外提一下,模型算蠻先進的。
重新做一次,只用 2 個 epochs。正確率 0.84。手動貓狗各測試 10 隻。結果有時錯的離譜。
2021/03/28。
-----
K02_Simple MNIST convnet(推薦:★★★★★ )
https://keras.io/examples/vision/mnist_convnet/
2021/03/29
可以很精簡地完成一個模型。
2021/03/29
-----
K03_Image segmentation with a U-Net-like architecture(推薦:★★★★★ )
https://keras.io/examples/vision/oxford_pets_image_segmentation/
2021/03/30
有趣的實作。經驗上 Colab 即使有 GPU,也沒辦法跑很快,所以把 15 個 epochs 改成 2 個,結果錯誤率還是高,而且跑不出結果。只好換回 15 再跑一次,順便在電腦上再做一點別的事。發現跑完後 Chrome 會有提示。實作完成,拍照留念。代碼後續研究一下。
2021/03/30。

-----
K04_3D Image Classification from CT Scans(推薦:★★★★★ )
https://keras.io/examples/vision/3D_image_classification/
里程碑四:3D Image Classification from CT Scans
2021/03/31
從 CT 取得的 3D 影像分類。有趣的實作,需要比較大一點點的運算量。第一次設 3 epochs,跑出來跟亂猜差不多。第二次設 30 epochs,第三次設為原值,結果提前結束,主要是 tf.keras.callbacks 的設定。感想,Colab 搭配 Keras 的 Tutorials,可以學到非常多東西。畢竟是免費的東西,這樣已經很好了。
http://www.taroballz.com/2020/02/24/DL_Tensorflow_keras_classifier_callbackFunc/
2021/03/31

-----
K05_Convolutional Autoencoder For Image Denoising(推薦:★★★★)
https://keras.io/examples/vision/autoencoder/
2021/04/01
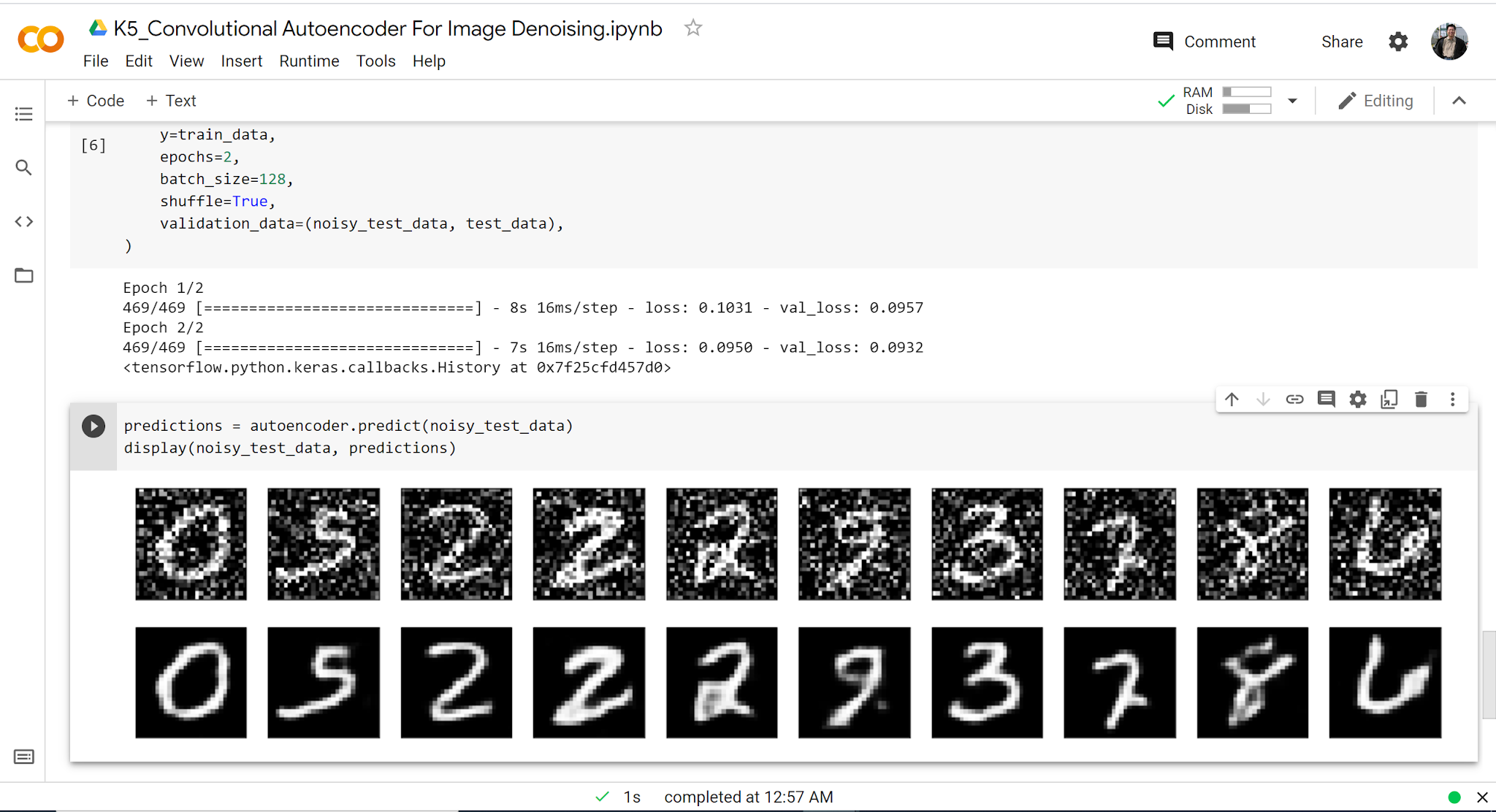
實作搭配論文,也許是一個比較理想的學習方式,畢竟大家先跑一下 code,有個東西出來,再去仔細思索背後的原理,會比較有動力。只是,得來容易,到底跑完東西後,有多少人會去仔細探究背後的原理呢?即使是我,從純理論,到開始實作,目前的策略,也只能儘快在 Colab 上跑完 Keras 的實作,再求其他。好處是之前論文已經看了很多,很多理論都已經嫻熟。只是理論到底每個人要深入到怎樣的層次,也是看每個人自己的需求,並無一定。
https://blog.keras.io/building-autoencoders-in-keras.html
回到實作,由於 Colab 的 GPU 速度不算快,所以我的策略是基本上先跑一下,有東西出來為主。本次實作,程式的預設值是 38/50 跟 84/100,程式自動停止。也就是 tf.keras.callbacks 的設定,early stopping,在 training error 已經不再降低時,訓練提前結束。
http://www.taroballz.com/2020/02/24/DL_Tensorflow_keras_classifier_callbackFunc/
觀察我的實驗跟原作者的實驗,我是剛好在第 2 次時,error 就變的夠小,所以得到跟原作者很像的結果,而原作者的程式設定,在一段時間之後,也發覺誤差已經很小,沒有新變化,所以程式就停止訓練了。
剛好就是了。剛好觀察到。有趣的現象。
-----
K06_OCR model for reading Captchas(推薦:★★★★)
https://keras.io/examples/vision/captcha_ocr/
2021/04/02
驗證碼辨識。照慣例先進行 2 個 epochs 就測試,結果無法辨識。10 個也不行。老實進行了 100 個,還好這個訓練算比較快。重新訓練 200 次,結果誤差又從小變大,10 次後自動結束。覺得這個實作蠻有趣的,但其實只是 MNIST 的應用而已。表面上有點無聊,但如果仔細研讀代碼,應該是可以學到很多東西。
2021/04/02

-----
K07_Next-frame prediction with Conv-LSTM(推薦:★ )
https://keras.io/examples/vision/conv_lstm/
2021/04/02
沒有明確的說明與結果。
2021/04/02
-----
K08_Grad-CAM class activation visualization(推薦:★★★★ )
https://keras.io/examples/vision/grad_cam/
2021/04/03
這是一個不大耗運算力的實作。主要是它使用預訓練模型 Xception 改進成為 Grad-CAM 的演算法,輸出除了原有的分類之外,也包含圖片的熱力圖。不要把熱力圖想成太複雜的東西,圖片裡面越有可能是分類的像素位置,溫度越高(顏色越紅)就對了。這個跟之前 NIN 的全局平均池化 GAP 有何不同呢?最主要是更細緻一點。那這跟 Visual Attention 有何不同呢?
先從 CAM 說起,CAM 立足在 GAP 上,模型最後一層需要修改成 GAP,重新訓練,想辦法取得熱力圖的輸出。重新訓練,很麻煩對不對?Grad-CAM 就是不用修改模型,也可以利用反向傳播,視覺化分類的一個演算法。
https://medium.com/%E6%89%8B%E5%AF%AB%E7%AD%86%E8%A8%98/grad-cam-introduction-d0e48eb64adb
之前被提出講解這篇論文,限於時間沒有辦法。這次遇到這個實作,或者說這個應用,可以仔細思考一下這個演算法。合適的位置我想不要在 ZFNet,也不要在 NIN 的時候講解,應該安排在 NLP 的 Attention 一起討論,會比較適合。
https://keras.io/zh/applications/
2021/04/03

-----
k09_Image classification via fine-tuning with EfficientNet(推薦:★★ )
https://keras.io/examples/vision/image_classification_efficientnet_fine_tuning/
2021/04/04
有用到 TPU 的設定,沒有完成。
2021/04/04
-----
K10_Image Classification with Vision Transformer(推薦:★★★★★★ )
--
https://keras.io/examples/vision/image_classification_with_vision_transformer/
2021/04/04
要先檢查 TensorFlow 的版本是否在 2.4 之後,
https://blog.csdn.net/u011961856/article/details/76861052
檢查結果,Colab 使用的是 2.4.1。但是要使用 addons,所以還是請照建議自行安裝。
由於訓練 100 次要很久,照慣例先訓練 2 次看一下結果。先前 num_epochs = 100 的設定,在最後一段代碼執行前,要重新設定 num_epochs = 2。
訓練 2 次的結果如下:

--
訓練 10 次的結果如下:

--
訓練 100 次的結果如下:

-----
https://zhuanlan.zhihu.com/p/340149804
--
里程碑五:
2021/04/04
前年年底,大量閱讀了一百多篇論文。去年一整年,仔細讀了一些論文,最經典的,應該是 NLP 的 Transformer。今年主要設定的目標是實作一堆 Keras 跟 PyTorch 的 Tutorials,以跟著代碼跑出結果為主,代碼部分不會特別加以研讀,因為理論部分,在大部分的論文裡面都讀過了。整個先跑完,看看有哪些實作是可以重複使用的,再來仔細研讀代碼。
Keras 實作的安排比 PyTorch 好,只要從頭到尾按照順序一直跑就可以了。三月底以來已經跑了九個有趣的實作,大部分都有照著完成。今天是第十個,Vision Transformer。
Transformer,或者說 NLP 的精華,是 QKV,Query、Key、Value。Key 跟 Value 不難理解,Key 就是 Index,Value 就是實際的意義。Query 是下一個字的機率分布。在序列資料如 NLP 等,Q 不難理解。在電腦視覺裡面,Q 應該是周邊像素的機率,這是我猜的,細節在論文裡面應該會有。剛剛看了一下論文的標題,再加上實作的 demo,知道作法是將一張圖片先拆成 16x16,也就是 256 個像素 x RGB 是一個字。知乎的文章,提到 Vision Transformer 在 Object Detection 上的應用是 DETR,也可以再看看。
代碼預設的訓練次數是 100。由於 Colab GPU 的速度不算快,按照慣例,我先跑 2 次,確定可以執行。再跑 10 次,看看損失函數的值跟正確率會不會隨的訓練有明顯的改變。最後才是 100 次整個跑完。
--
2021/04/05
由於結果不算好,試著把 dropout 從 0.5 調到 0.9,結果根本訓練不起來。中間就強迫停止,換成 0.1 重新試一遍。看起來結果還不壞,先觀察一下。
2021/04/05


--
2021/04/06
重新以原設定跑 20 次,結果如下:
Test accuracy: 45.07% Test top 5 accuracy: 74.87%
50 次的結果如下:
Test accuracy: 53.99% Test top 5 accuracy: 81.15%
50 次的結果大約與 100 次相當。但是 ResNet50V2 的結果是 67% 的正確率。原論文之所以效果很好是因為先在 JFT-300M 資料集上預訓練。除了預訓練之外,實作的作者建議,調整各種超參數與模型架構也有助於結果。
2021/04/06
-----
K11_Model interpretability with Integrated Gradients(推薦:★★★★★ )
https://keras.io/examples/vision/integrated_gradients/
2021/04/04
順利跑完。以下是積分梯度很棒的解釋文章,並有更簡潔的實作代碼。
https://spaces.ac.cn/archives/7533
2021/04/04

-----
K12_Knowledge Distillation(推薦:★★★ )
https://keras.io/examples/vision/knowledge_distillation/
2021/04/05
可以很容易照著跑完。沒有漂亮的圖,只有簡單的結果呈現。這個應該算是遷移學習,就是把老師模型的結果蒸餾給學生模型。跟學生重頭訓練的結果比較,其實不大能看出明顯的結果。2015 年的論文被選入實作,這篇應該也算是 Hinton 大師的經典之一吧。
2021/04/05

-----
K13_Metric learning for image similarity search(推薦:★★★ )
https://keras.io/examples/vision/metric_learning/
2021/04/06
無法判定這個的重要性。
2021/04/06

-----
K14_MixUp augmentation for image classification(推薦:★★★ )
https://keras.io/examples/vision/mixup/
2021/04/07
fashion_mnist 是一個小資料集,所以訓練沒有很花時間。範例上的結果是有擴增好一點點,我的結果是沒有擴增好一點點。大體上可以說沒有明顯的差異。
標籤平滑和混合通常不能很好地協同工作,因為標籤平滑已經在一定程度上修改了硬標籤。
--
Epoch 1/10 907/907 [==============================] - 39s 42ms/step - loss: 1.4161 - accuracy: 0.5456 - val_loss: 0.6868 - val_accuracy: 0.7460 Epoch 2/10 907/907 [==============================] - 37s 40ms/step - loss: 0.9624 - accuracy: 0.7173 - val_loss: 0.5749 - val_accuracy: 0.7920 Epoch 3/10 907/907 [==============================] - 38s 42ms/step - loss: 0.8824 - accuracy: 0.7559 - val_loss: 0.5176 - val_accuracy: 0.8105 Epoch 4/10 907/907 [==============================] - 38s 42ms/step - loss: 0.8270 - accuracy: 0.7823 - val_loss: 0.4576 - val_accuracy: 0.8405 Epoch 5/10 907/907 [==============================] - 38s 42ms/step - loss: 0.7785 - accuracy: 0.8007 - val_loss: 0.4351 - val_accuracy: 0.8540 Epoch 6/10 907/907 [==============================] - 38s 42ms/step - loss: 0.7628 - accuracy: 0.8062 - val_loss: 0.4239 - val_accuracy: 0.8565 Epoch 7/10 907/907 [==============================] - 38s 42ms/step - loss: 0.7399 - accuracy: 0.8121 - val_loss: 0.3999 - val_accuracy: 0.8645 Epoch 8/10 907/907 [==============================] - 38s 42ms/step - loss: 0.7220 - accuracy: 0.8207 - val_loss: 0.3794 - val_accuracy: 0.8665 Epoch 9/10 907/907 [==============================] - 39s 43ms/step - loss: 0.7087 - accuracy: 0.8226 - val_loss: 0.3724 - val_accuracy: 0.8705 Epoch 10/10 907/907 [==============================] - 38s 42ms/step - loss: 0.7070 - accuracy: 0.8250 - val_loss: 0.3647 - val_accuracy: 0.8720 157/157 [==============================] - 2s 13ms/step - loss: 0.3886 - accuracy: 0.8665 Test accuracy: 86.65%--
Epoch 1/10 907/907 [==============================] - 38s 41ms/step - loss: 1.1799 - accuracy: 0.5798 - val_loss: 0.6595 - val_accuracy: 0.7440 Epoch 2/10 907/907 [==============================] - 37s 41ms/step - loss: 0.6523 - accuracy: 0.7504 - val_loss: 0.5687 - val_accuracy: 0.7770 Epoch 3/10 907/907 [==============================] - 38s 42ms/step - loss: 0.5675 - accuracy: 0.7887 - val_loss: 0.5080 - val_accuracy: 0.8320 Epoch 4/10 907/907 [==============================] - 38s 41ms/step - loss: 0.5041 - accuracy: 0.8156 - val_loss: 0.4635 - val_accuracy: 0.8335 Epoch 5/10 907/907 [==============================] - 37s 41ms/step - loss: 0.4672 - accuracy: 0.8309 - val_loss: 0.4338 - val_accuracy: 0.8530 Epoch 6/10 907/907 [==============================] - 37s 41ms/step - loss: 0.4363 - accuracy: 0.8409 - val_loss: 0.3991 - val_accuracy: 0.8650 Epoch 7/10 907/907 [==============================] - 38s 41ms/step - loss: 0.4132 - accuracy: 0.8505 - val_loss: 0.3881 - val_accuracy: 0.8675 Epoch 8/10 907/907 [==============================] - 38s 42ms/step - loss: 0.3938 - accuracy: 0.8581 - val_loss: 0.3592 - val_accuracy: 0.8740 Epoch 9/10 907/907 [==============================] - 38s 42ms/step - loss: 0.3817 - accuracy: 0.8615 - val_loss: 0.3577 - val_accuracy: 0.8735 Epoch 10/10 907/907 [==============================] - 38s 41ms/step - loss: 0.3673 - accuracy: 0.8653 - val_loss: 0.3464 - val_accuracy: 0.8785 157/157 [==============================] - 2s 14ms/step - loss: 0.3668 - accuracy: 0.8702 Test accuracy: 87.02%
--
-----
K15_Point cloud classification with PointNet(推薦:★★★ )
https://keras.io/examples/vision/pointnet/
2021/04/08
注意:
要先安裝 trimesh,最新版是 3.9.12,我安裝 3.9.10 即可成功繼續執行。
-----
要先安裝 trimesh
pip install trimesh==2.38.39
https://github.com/mikedh/trimesh/issues/499
--
其實是要更新到 3.9.10 的最新版。
https://github.com/facebookresearch/votenet/issues/40
又,最新版已經是 3.9.12。
--
訓練兩次的結果,正確率是 3/8,範例訓練 20 次,正確率是 6/8。
重新訓練 20 次,正確率是 7/8。
--
2021/04/08

-----
K16_RandAugment for Image Classification for Improved Robustness.(推薦:★ )
https://keras.io/examples/vision/randaugment/
2021/04/12
--
說明:
有解決兩個問題。但執行時,使用 Colab 的 GPU,到 36 分鐘還在跑,決定中止。GPU 速度較快者,可以嘗試看看。
--
一開始,將
pip install imgaug
改成
pip install imgaug==0.4.0
使用較新的版本,即可免除後續的 bug。iaa.RandAugment 找不到的問題。
--
print(get_training_model().summary() # 漏掉一個右括號。
--
2021/04/12
-----
K17_Few-Shot learning with Reptile(推薦:★★)
2021/04/13
運算不是太費時。
小樣本的遷移學習訓練?
2021/04/13
-----
K18_Object Detection with RetinaNet(推薦:★★★★★ )
https://keras.io/examples/vision/retinanet/
2021/04/15
比起之前 LeNet,代碼算是有點長了。
--
# Uncomment the following lines, when training on full dataset
# train_steps_per_epoch = dataset_info.splits["train"].num_examples // batch_size
# val_steps_per_epoch = \
# dataset_info.splits["validation"].num_examples // batch_size
# train_steps = 4 * 100000
# epochs = train_steps // train_steps_per_epoch
epochs = 1
# Running 100 training and 50 validation steps,
# remove `.take` when training on the full dataset
model.fit(
train_dataset.take(100),
validation_data=val_dataset.take(50),
epochs=epochs,
callbacks=callbacks_list,
verbose=1,
)
--
最後一段的代碼如上。
今天忘記設 GPU,結果超慢。
# Running 100 training and 50 validation steps,
設了 GPU 之後,100 個 training steps 可以很快跑完。
結果還是把訓練好的權重叫出來,然後示範一下。

2021/04/15
-----
K19_Semantic Image Clustering(推薦:★★★)
https://keras.io/examples/vision/semantic_image_clustering/
2021/04/16
說明:
Keras 挑選實作的標準是什麼?
預設值 epochs 50,建議值 500,照慣例先 2。結果比原實作差一些。然後換 10 再跑一遍,有好一些。
本實作的原論文是 2020 年,算新。被引用次數目前 25,不算多,也不算少。主要讓我去想一個問題,Keras 挑選實作的標準是什麼?裡面的原論文,有簡單的,也有難的。有經典的,也有新的。目的應該是協助入門者快速進入深度學習的領域?但這些實作的量已經有點多了,實作的碼雖然已經公布,但要讀懂原始論文,也要花一些功夫。另外,新論文的量還是很驚人。研究生或研究者還好,反正是鎖定一個主題。若以整個深度學習的海量論文來說,Keras 選的量,也還是算少的,作為開始,應該還是很不錯的。
Keras 挑選實作的標準是什麼?
--

10 次也看一下。

結論
為了提高準確性結果,您可以:1)增加表示學習和聚類階段的 epochs; 2)允許在聚類階段調整編碼器權重; 和3)如原始 SCAN 論文所述,通過自標記執行最後的微調步驟。 請注意,無監督的圖像聚類技術不會超過監督的圖像分類技術的準確性,而是表明它們可以學習圖像的語義並將其分組為與原始類相似的聚類。
2021/04/16
-----
K20_Image similarity estimation using a Siamese Network with a triplet loss(推薦:★★★★★ )
https://keras.io/examples/vision/siamese_network/
2021/04/17
預設訓練 10 個 epochs,實際訓練 2 個,結果就不錯了。
實作到目前廿次,覺得即使是 Keras,實作還是很難的,特別是要把 Code 看懂的話,其實也要看懂論文。
2021/04/17
-----
K21_Self-supervised contrastive learning with SimSiam
https://keras.io/examples/vision/simsiam/
2021/04/17
減少對於大量標註資料的依賴。
--
說說對深度學習與 Keras 的想法。
實作與實戰。
實作 Keras 超過廿個了。
並沒有很仔細去研讀代碼,主要是跑完,確定如果有需要,可以使用這個實作的代碼。讀論文,是基礎的累積,跑實作,也是基礎的累積,基礎累積到多少,才能投入到實戰?如果以台灣而言,老闆最喜歡的,應該是名校的電機資工碩士,深度學習實驗室,的畢業生。
能投入實戰,應該是比較重要的一環,因為如果一直累積,要累積的方向比較廣,重點其實分散了。投入實戰的話,有收入,也能持續累積實戰該領域的知識,比較集中。碩士班兩年,專注於一個題目,算是為實戰的目的,長期的投入。
以上是對論文、實作、實戰的一些雜感。
2021/04/17
-----
K22_Image Super-Resolution using an Efficient Sub-Pixel CNN(推薦:★★★★★ )
https://keras.io/examples/vision/super_resolution_sub_pixel/
2021/04/18
預設用 100 epochs,先用 2 epochs,可以跑完。
那麼,這個實作在做什麼事呢?
實作一開始的訊息如下:Shi,2016年提出的ESPCN(高效子像素CNN)是一種模型,可在給定低分辨率版本的情況下重建圖像的高分辨率版本。 它利用有效的“子像素卷積”層,學習了一系列圖像放大濾波器。
這個厲害。實作選這個是正確的。
2021/04/18
-----
K23_Supervised Contrastive Learning(推薦:★★)
https://keras.io/examples/vision/supervised-contrastive-learning/
2021/04/19
Keras CV 的實作快跑完了,小結一下,並不像我原先想的,一個一個一直跑下去就可以。難易度的區別也是大小不一,不一定適合初學者自行練習。
50 個 epochs 有跑完。
2021/04/19
-----
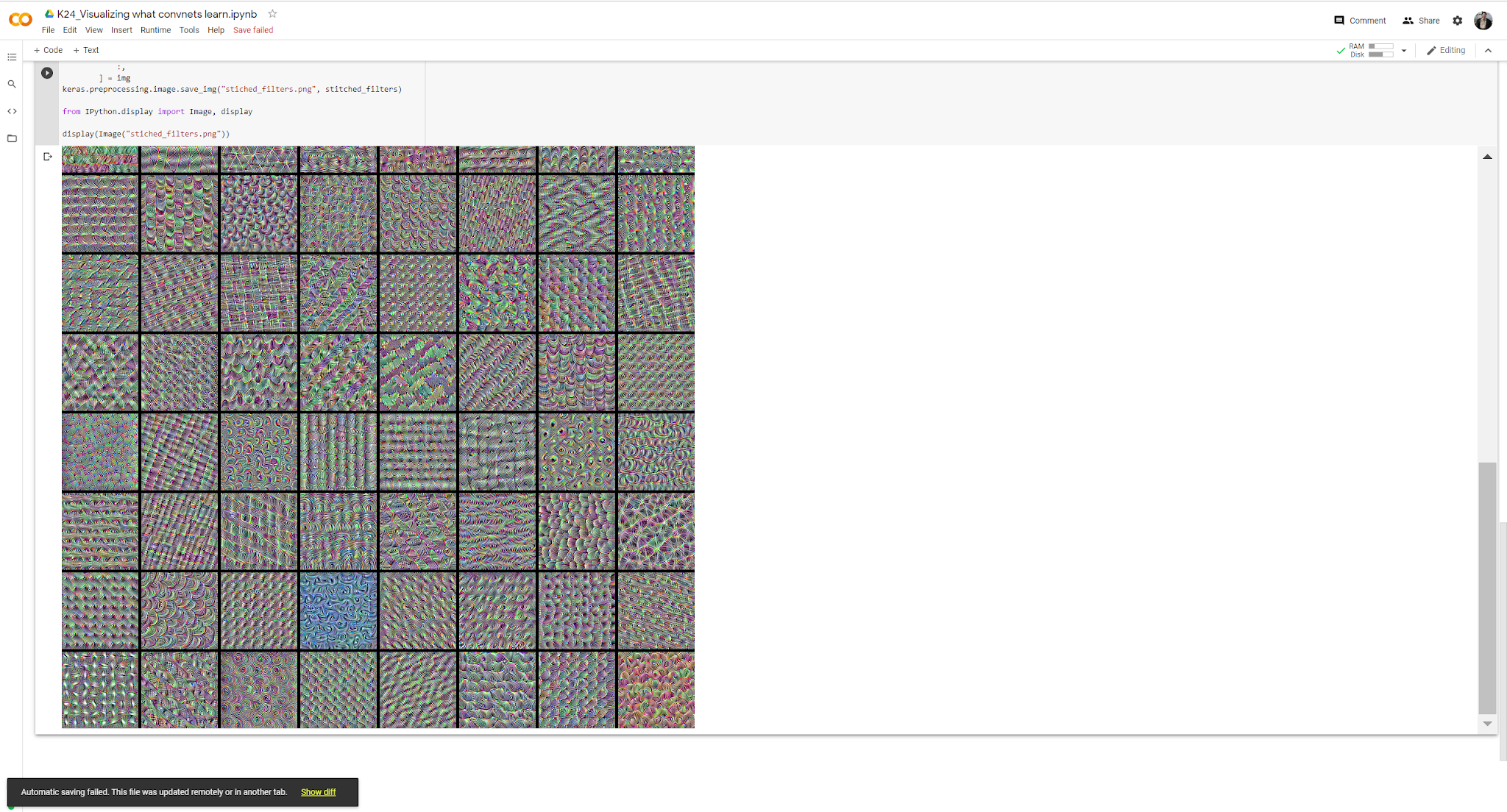
K24_Visualizing what convnets learn(推薦:★★★★★ )
2021/04/20
實用的技巧。
--
2021/04/20
-----
K25_Pneumonia Classification on TPU(推薦:★★★★★)
https://keras.io/examples/vision/xray_classification_with_tpus/
2021/04/20
這個重點應該是 TPU。果然很快。100 個 epochs,沒注意到就讓它跑了,真的很快。然後 100 也沒跑完,提前結束。
--

2021/04/20
-----
里程碑七
2021/04/20
終於跑完了 Keras 25 個 CV 的實作,某方面應該說是跑過了,而非跑完了。
心得當然是有一些,與其說是心得,不如說是感想。
首先,記錄是好事,03/28 開始第一個,今天 04/20 是第 25 個,大約一天「完成」一個。我沒有花太多時間去鑽研某一個,因為主要目的,是要先找出哪些實作比較適合練習。這些實作有難有易。不是簡單的就適合練習,也不是難的就要避開。有明確結果的,比較適合,特別是有圖。
就,接下來是 NLP 11 個實作,然後是其他 25 個,然後是快速上手 8 個,Keras 的實作就結束了。接下來預計的是 TensorFlow 與 PyTorch。有人建議要找一個主題仔細鑽研,這是的,之前博士班的時候,就是這樣搞的。希望五月份可以出現這樣的一個機會。
-----
K26_Text classification from scratch(推薦:★★★★★)
https://keras.io/examples/nlp/text_classification_from_scratch/
2021/04/21
TextVectorization 是重點。
一維卷積。不是 LSTM。
https://ithelp.ithome.com.tw/articles/10244283
2021/04/21
-----
K27_Sequence to sequence learning for performing number addition(推薦:★★★★★)
https://keras.io/examples/nlp/addition_rnn/
2021/04/21
這是一個很簡單的實作,也很有趣。加法器。架構是 LSTM。資料可以自己生成。一開始錯很多,進行到十五次以後,基本上就正確了。
2021/04/21
--


-----
K28_Bidirectional LSTM on IMDB(推薦:★★★★★)
https://keras.io/examples/nlp/bidirectional_lstm_imdb/
2021/04/22
代碼很短。模型的架構可以研究一下。
2021/04/22

-----
K29_Character-level recurrent sequence-to-sequence model(推薦:★★★★★)
https://keras.io/examples/nlp/lstm_seq2seq/
2021/04/22
先訓練 2 個 epochs,結果跑出來都是 Tome。再訓練 10 次,結果跑出來的字有變化,但都是錯的。最後訓練一百次。英法翻譯,沒有確定訓練結果是否正確。
2021/04/22
-----
K30_End-to-end Masked Language Modeling with BERT(推薦:★)
https://keras.io/examples/nlp/masked_language_modeling/
2021/04/22
訓練速度很慢,中途把它停掉。
2021/04/22
-----
K31_Natural language image search with a Dual Encoder(推薦:★)
https://keras.io/examples/nlp/nl_image_search/
2021/04/22
資料檔太大。模型太大。無明確結果。無明確論文。
2021/04/22
-----
K32_Using pre-trained word embeddings(推薦:★)
https://keras.io/examples/nlp/pretrained_word_embeddings/
2021/04/22
在此示例中,我們顯示瞭如何訓練使用預訓練詞嵌入的文本分類模型。我們將使用 Newsgroup20 數據集,該數據集是一組 20,000 個留言板消息,分別屬於 20 個不同的主題類別。對於預訓練的單詞嵌入,我們將使用 GloVe 嵌入。
無明確結果。沒有跑完。
2021/04/22
-----
K33_Semantic Similarity with BERT(推薦:★)
https://keras.io/examples/nlp/semantic_similarity_with_bert/
2021/04/23
句子的相似度。
TypeError: Inputs to a layer should be tensors. Got: last_hidden_state
建模時發生錯誤,沒有跑完。
2021/04/23

-----
K34_Text classification with Switch Transformer(推薦:★)
https://keras.io/examples/nlp/text_classification_with_switch_transformer/
2021/04/23
與標準 Transformer 架構相比,Switch Transformer 可以具有更多的參數,從而提高了模型容量,同時又保持了合理的計算成本。
2021/04/23
-----
K35_Text classification with Transformer(推薦:★)
https://keras.io/examples/nlp/text_classification_with_transformer/
2021/04/23
將 Transformer 塊實現為 Keras 層,並將其用於文本分類。
2021/04/23
-----
K36_Text Extraction with BERT(推薦:★)
https://keras.io/examples/nlp/text_extraction_with_bert/
2021/04/23
pip install tokenizers
pip install transformers
NameError: name 'tokenizer' is not defined
pip install tokenizers
pip install transformers
NameError: name 'tokenizer' is not defined
2021/04/23
-----
K37_Structured data classification from scratch(推薦:★★★★★)
https://keras.io/examples/structured_data/structured_data_classification_from_scratch/
2021/04/24
dataframe 的示範。典型的例子,用淺層的神經網路預測新案例。
資料不多,50 個 epochs 一下子跑完,預測心臟病。
2021/04/24

-----
K38_Classification with Gated Residual and Variable Selection Networks(推薦:?)
https://keras.io/examples/structured_data/classification_with_grn_and_vsn/
2021/04/24
使用門控殘差和變量選擇網路進行收入水平預測。
2021/04/24

-----
K39_Collaborative Filtering for Movie Recommendations(推薦:★★★★★)
https://keras.io/examples/structured_data/collaborative_filtering_movielens/
2021/04/26
Item-based collaborative filtering recommendation algorithms。2001 年的論文。被引用 9930 次。
Neural Collaborative Filtering。2017 年的論文。被引用 2113 次。
https://blog.csdn.net/Gamer_gyt/article/details/105009253
2021/04/26

-----
K40_Classification with Neural Decision Forests(推薦:★★★)
https://keras.io/examples/structured_data/deep_neural_decision_forests/
2021/04/26
Deep neural decision forests。2015 的論文,被引用 361 次。基本上是個有趣的嘗試。但覺得實用性不是太高,所以只給三顆星的推薦。
執行的速度很快。
2021/04/26

-----
K41_Imbalanced classification: credit card fraud detection(推薦:?)
https://keras.io/examples/structured_data/imbalanced_classification/
2021/04/27
先到 kaggle 下載檔案。
2021/04/27
-----
K42_A Transformer-based recommendation system(推薦:?)
https://keras.io/examples/structured_data/movielens_recommendations_transformers/
2021/04/27
Behavior sequence transformer for e-commerce recommendation in alibaba。2019 的論文,被引用 46 次。
有照著跑出結果。
2021/04/27
-----
K43_Structured data learning with Wide, Deep, and Cross networks(推薦:?)
https://keras.io/examples/structured_data/wide_deep_cross_networks/
2021/04/27
NameError: name 'hidden_units' is not defined
2021/04/27
-----
K44_Timeseries anomaly detection using an Autoencoder(推薦:★★★★★)
https://keras.io/examples/timeseries/timeseries_anomaly_detection/
2021/04/27
一維卷積偵測時間序列中的不正常。應該是蠻實用的。
2021/04/27

-----
K45_Timeseries classification from scratch(推薦:★★★★★)
https://keras.io/examples/timeseries/timeseries_classification_from_scratch/
2021/04/28
一維卷積。先跑 2 個 epochs。再跑 500 個 epochs。其實運算超快的。336 時提前結束。
2021/04/28

--

-----
K46_Timeseries forecasting for weather prediction(推薦:★★★★★)
https://keras.io/examples/timeseries/timeseries_weather_forecasting/
2021/04/28
用 LSTM 預測天氣。10 個 epochs,速度不快,但可以跑完。
2021/04/28

-----
K47_Speaker Recognition(推薦:?)
2021/04/28
要另行先處理 kaggle 的新資料。
2021/04/28
-----
K48_Automatic Speech Recognition with Transformer(推薦:★)
https://keras.io/examples/audio/transformer_asr/
2021/04/28
下載資料要 5 分鐘以上。1 個 epoch 就很慢。在實踐中,您應該訓練大約 100 個 epochs 或更長時間。
2021/04/28
--
-----
K49_Variational AutoEncoder(推薦:★★★★★)
https://keras.io/examples/generative/vae/
2021/04/29
先跑 2 個 epochs,已經有一個樣子,但是分布跟範例差很多。跑的速度很快,所以再重新跑 50 個 epochs,出來的阿拉伯數字比較豐富了,分布跟範例比較接近。實作很新,是 2020 年的,但沒附論文。
https://www.tensorflow.org/tutorials/generative/cvae
TensorFlow 的實作版本則附有三篇以上的論文。
2021/04/29


--
里程碑八
2021/04/29
前一段時間(大約一個月)已經跑過(非仔細跑完)Keras 48 個實作,本來是想要等到生成模型 10 個,強化學習 3 個,recipes 8 個跑完(大約要兩個禮拜),再來下里程碑。不過生成模型第一個實作 VAE 很有趣,也是之前排在學習清單的項目,所以先說說感想。
跑實作,大部分很簡單,反正代碼別人已經寫好了,而且現在的實作,說明也越來越清楚。但如果很快跑完,沒有仔細 trace 代碼,得到的效益很淺。如果沒有再去仔細讀論文,只知其然而不知其所以然,得到的效益也是不高。
反過來,讀論文,如果沒有落實到實作,也算是在打高空。深度學習雖然幾乎都是數學,但畢竟這個不是數學,不是只有數學的理論要證明,而是資工的代碼要實現。
後續還是等整個 Keras 的範例實作先跑完,然後再選幾個應用面可以落實的實作仔細研究,深入瞭解。另外一個則是也開始跑一下 TensorFlow 的實作。時間大概是太陽進雙子座的時候,我很期待。
--


-----
K50_DCGAN to generate face images(推薦:★)
https://keras.io/examples/generative/dcgan_overriding_train_step/
2021/04/29
跑一個 epoch 就要很久。範例示範的是 30 個 epochs。原實作建議的是 100 以上。
2021/04/29
-----
K51_WGAN-GP overriding(推薦:★★★★★)
https://keras.io/examples/generative/wgan_gp/
2021/04/30
跑的速度不快,照例先跑 2 個 epochs,但圖片沒有顯現成功。然後照預設值跑 20 個 epochs,花了 40 幾分鐘,最後成功顯現圖片。
2021/04/30

--

-----
K52_Neural style transfer(推薦:★★★★★)
https://keras.io/examples/generative/neural_style_transfer/
2021/04/30
速度不快,但可以跑完。
2021/04/30
-----
K53_Deep Dream(推薦:★★★★★)
2021/05/01
跑的速度很快。
2021/05/01

-----
K54_CycleGAN(推薦:★★★★★)
https://keras.io/examples/generative/cyclegan/
2021/05/01
要先裝 tensorflow-addons
pip install tensorflow-addonshttps://github.com/tensorflow/addons/issues/241
--
NameError: name 'train_horses' is not defined
漏搬一塊代碼。參考其他 TensorFlow 實作後發現。
--
原實作示範訓練一個 epoch,然後下載一個訓練 90 epochs 的權重,下方是範例圖片。
--

--
中文參考文章
https://medium.com/hoskiss-stand/cycle-gan-note-bd166d9ff176
2021/05/01
-----
K55_Character-level text generation with LSTM(推薦:★★★★★)
https://keras.io/examples/generative/lstm_character_level_text_generation/
2021/05/02
沒有附論文。
2021/05/02
-----
K56_PixelCNN(推薦:★★★★)
https://keras.io/examples/generative/pixelcnn/
2021/05/03
2016 的論文,有點舊了。重要,但不是最重要。實作建議跑 50 個 epochs,但因為有點慢,2 個之後就中斷,直接看結果,出來的圖確實不成為圖。重新跑 50 個,放著離開,在 21 時,系統停止,無法執行顯示圖片。
2021/05/03
-----
K57_Density estimation using Real NVP(推薦:★★★★★)
https://keras.io/examples/generative/real_nvp/
2021/05/03
2016 的論文,不算新了。1000 多次引用,還不錯。
https://blog.csdn.net/daydayjump/article/details/85041564
流模型。屬於較進階的主題。epochs 先從 300 降到 3,速度超快,跑出有點好笑的結果。重跑一次,跑出跟實作一樣的結果。後續有時間再來研究論文。
2021/05/03
--

--

-----
K58_Text generation with a miniature GPT(推薦:?)
https://keras.io/examples/generative/text_generation_with_miniature_gpt/
2021/05/03
GPT 系列的生成模型。訓練的速度很慢。沒有跑完。
2021/05/03
-----
K59_Actor Critic Method(推薦:★★★★★)
https://keras.io/examples/rl/actor_critic_cartpole/
2021/05/03
程式很短,結果明確。episode 380 時分數 193 接近 195 收斂標準,最後在 episode 671 時完成。
2021/05/03

-----
K60_Deep Deterministic Policy Gradient (DDPG)(推薦:★★★★★)
https://keras.io/examples/rl/ddpg_pendulum/
2021/05/03
深度確定性策略梯度(DDPG)是用於學習連續動作的無模型偏離策略算法。它結合了 DPG(確定性策略梯度)和 DQN(深層 Q 網路)的思想。 它使用 DQN 的 Experience Replay 和慢速學習目標網路,並且基於 DPG,可以在連續的動作空間上進行操作。
問題描述:我們正在嘗試解決經典的倒立擺控制問題。 在這種設置下,我們只能執行兩個操作:向左擺動或向右擺動。使這個問題對 Q 學習算法具有挑戰性的原因是動作是連續的而不是離散的。 也就是說,我們不必使用兩個離散的動作(如 -1 或 +1),而必須從 -2 到 +2 的無限動作中進行選擇。
代碼不長,訓練速度很快。
2021/05/03

-----
K61_Deep Q-Learning for Atari Breakout(推薦:★)
https://keras.io/examples/rl/deep_q_network_breakout/
2021/05/03
pip install baselines
https://pypi.org/project/baselines/
要先安裝 baselines。
--
訓練上有點慢。注意:Deepmind 論文針對“總共 5000 萬幀(即總共約 38 天的遊戲體驗)”進行了訓練。 但是,此腳本將在大約 1000 萬幀的情況下提供良好的效果,這些幀可以在一台現代計算機上在不到 24 小時的時間內進行處理。
2021/05/03
-----
K62_Simple custom layer example: Antirectifier(推薦:★)
https://keras.io/examples/keras_recipes/antirectifier/
2021/05/03
MNIST 使用 ReLU 的替代。
2021/05/03

-----
K63_Probabilistic Bayesian Neural Networks(推薦:?)
https://keras.io/examples/keras_recipes/bayesian_neural_networks/
2021/05/05
TimeoutError: [Errno 110] Connection timed out
2021/05/05
-----
K64_Creating TFRecords(推薦:★★★★★)
https://keras.io/examples/keras_recipes/creating_tfrecords/
2021/05/05
此範例說明,由於有了 TFRecord,您可以使資料來自單一來源,而不是從不同來源讀取圖像和註釋。 此過程可以使儲存和讀取資料更簡單,更有效。 有關更多資訊,您可以轉到 TFRecord 和 tf.train.Example 教程。
2021/05/05

-----
K65_Keras debugging tips(推薦:★★★★★)
https://keras.io/examples/keras_recipes/debugging_tips/
2021/05/06
2021/05/06
-----
-----
References
[1] Code examples
[2] GitHub - mc6666/Keras_tutorial
https://github.com/mc6666/Keras_tutorial/
-----
# 有時訓練會提前結束,那是因為。。。
[3] Tensorflow2-tensorflow-keras-回調函數 | Taroballz StudyNotes
http://www.taroballz.com/2020/02/24/DL_Tensorflow_keras_classifier_callbackFunc/
# 2 次,損失函數的值就降到很低。奇特的現象。
[4] Building Autoencoders in Keras
https://blog.keras.io/building-autoencoders-in-keras.html
-----
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.