[翻譯] 5 algorithms to train a neural network
2020/10/02
-----

https://www.neuraldesigner.com/blog/5_algorithms_to_train_a_neural_network
Fig. 1. 5 algorithms to train a neural network。
-----
The procedure used to carry out the learning process in a neural network is called the optimization algorithm (or optimizer).
用於在神經網路中執行學習過程的過程稱為優化算法(或優化器)。
There are many different optimization algorithms. All have different characteristics and performance in terms of memory requirements, processing speed, and numerical precision.
有許多不同的優化算法。 就內存需求,處理速度和數值精度而言,所有算法都有不同的特性和表現。
In this post, we formulate the learning problem for neural networks. Then, some important optimization algorithms are described. Finally, the memory, speed, and precision of those algorithms are compared.
在這篇文章中,我們制定了神經網路的學習問題。 然後,描述了一些重要的優化算法。 最後,比較了這些算法的內存,速度和精度。
-----

https://www.neuraldesigner.com/blog/5_algorithms_to_train_a_neural_network
Fig. 2. 5 algorithms to train a neural network。
-----
Learning problem.
1. Gradient descent.
2. Newton method.
3. Conjugate gradient.
4. Quasi-Newton method.
5. Levenberg-Marquardt algorithm.
Performance comparison.
Conclusions.
學習問題。
1. 梯度下降。
2. 牛頓法。
3. 共軛梯度。
4. 擬牛頓法。
5. 萊文貝格-馬夸特方法。
性能比較。
結論。
Neural Designer implements a great variety of optimization algorithms to ensure that you always achieve the best models from your data. You can download a free trial here.
Neural Designer 實現了各種各樣的優化算法,以確保您始終從數據中獲得最佳模型。 您可以在此處下載免費試用版。
-----
Learning Problem
-----
The learning problem is formulated in terms of the minimization of a loss index, f. It is a function that measures the performance of a neural network on a data set.
學習問題是根據損耗指數 f 的最小化來表述的。 它是一項測量數據集上神經網路性能的函數。
The loss index is, in general, composed of an error and a regularization terms. The error term evaluates how a neural network fits the data set. The regularization term is used to prevent overfitting by controlling the sufficient complexity of the neural network.
損耗指數通常由錯誤和正則項組成。 誤差項評估神經網路如何擬合數據集。 正則化項用於通過控制神經網路的足夠複雜性來防止過度擬合。
The loss function depends on the adaptative parameters (biases and synaptic weights) in the neural network. We can conveniently group them into a single n-dimensional weight vector w.
損失函數取決於神經網路中的自適應參數(偏置和突觸權重)。 我們可以方便地將它們分組為單個 n 維權重向量 w。
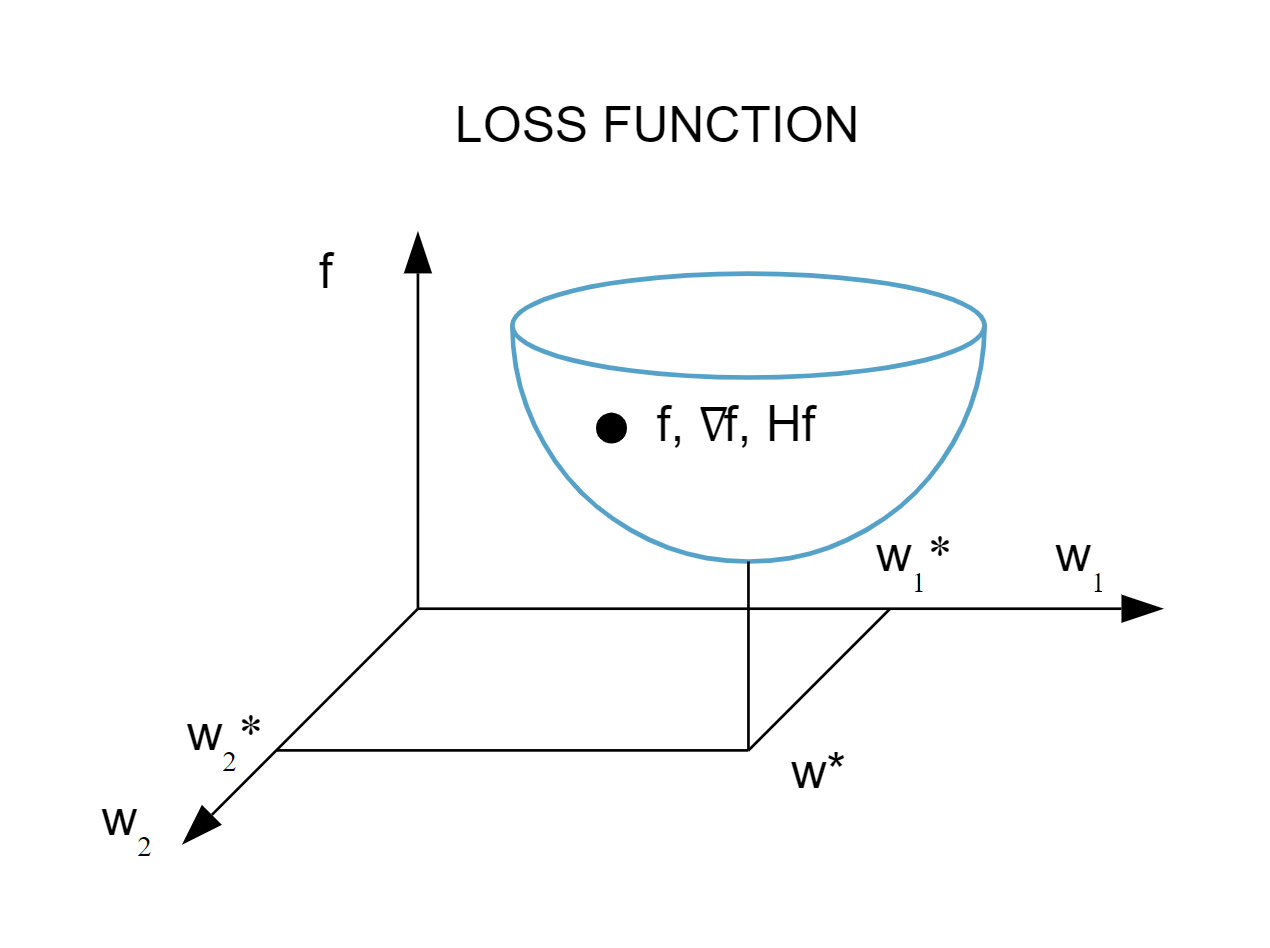
The picture below represents the loss function f(w).
下圖顯示了損失函數 f(w)。
-----
-----

Fig. 4. The first derivatives。
-----
As we can see in the previous picture, the minimum of the loss function occurs at the point w∗. At any point A, we can calculate the first and second derivatives of the loss function.
如上圖所示,損失函數的最小值出現在 w * 點。 在任何一點 A,我們都可以計算損失函數的一階和二階導數。
The first derivatives are grouped in the gradient vector, whose elements can be written as ... for i = 1, … , n.
一階導數在梯度向量中分組,對於 i = 1,…,n,其元素可以寫成 ...。
Similarly, the second derivatives of the loss function can be grouped in the Hessian matrix, for i, j = 0, 1, … .
類似地,對於 i,j = 0,1,…,損失函數的二階導數可以分組在 Hessian 矩陣中。
The problem of minimizing the continuous and differentiable functions of many variables has been widely studied. Many of the conventional approaches to this problem are directly applicable to that of training neural networks.
最小化多變量的連續和可微函數的問題已被廣泛研究。 解決該問題的許多常規方法可直接應用於訓練神經網路。
-----
One-dimensional optimization
-----
Although the loss function depends on many parameters, one-dimensional optimization methods are of great importance here. Indeed, they are very often used in the training process of a neural network.
儘管損失函數取決於多參數,但是一維優化方法在這裡非常重要。 確實,它們經常在神經網路的訓練過程中使用。
Many training algorithms first compute a training direction d and then a training rate η; that minimizes the loss in that direction, f(η). The next picture illustrates this one-dimensional function.
許多訓練算法首先計算訓練方向 d,然後計算訓練速率 η; 從而使該方向上的損耗 f(η)最小。 下一張圖片說明了此一維函數。
-----

Fig. 5. Interval。
-----
The points η1 and η2 define an interval that contains the minimum of f, η∗.
點 η1 和 η2 定義了一個包含 f 的最小值 η∗ 的區間。
In this regard, one-dimensional optimization methods search for the minimum of a given one-dimensional function. Some of the algorithms which are widely used are the golden section method and Brent's method. Both reduce the bracket of a minimum until the distance between the two outer points in the bracket is less than a defined tolerance.
在這方面,一維優化方法搜索給定一維函數的最小值。 廣泛使用的一些算法是黃金分割法和布倫特法。 兩者都會減小區間中的最小值,直到區間中兩個外部點之間的距離小於定義的公差為止。
-----
Multidimensional optimization
-----
The learning problem for neural networks is formulated as searching of a parameter vector w∗ at which the loss function f takes a minimum value. The necessary condition states that if the neural network is at a minimum of the loss function, then the gradient is the zero vector.
神經網路的學習問題被表述為搜索參數向量 w∗,其中損失函數 f 取最小值。 必要條件表明,如果神經網路處於損失函數的最小值,則梯度為零向量。
The loss function is, in general, a non-linear function of the parameters. As a consequence, it is not possible to find closed training algorithms for the minima. Instead, we consider a search through the parameter space consisting of a succession of steps. At each step, the loss will decrease by adjusting the neural network parameters.
損失函數通常是參數的非線性函數。 結果,不可能找到針對最小值的封閉訓練算法。 相反,我們考慮在由一系列步驟組成的參數空間中進行搜索。 在每一步,通過調整神經網路參數,損耗將減少。
In this way, to train a neural network, we start with some parameter vector (often chosen at random). Then, we generate a sequence of parameters, so that the loss function is reduced at each iteration of the algorithm. The change of loss between two steps is called the loss decrement. The training algorithm stops when a specified condition, or stopping criterion, is satisfied.
這樣,為了訓練神經網路,我們從一些參數向量開始(通常是隨機選擇)。 然後,我們生成一系列參數,以便在算法的每次迭代中減少損失函數。 兩步之間的損耗變化稱為損耗減量。 當滿足指定條件或停止標準時,訓練算法停止。
-----
1. Gradient descent
-----
Gradient descent, also known as steepest descent, is the most straightforward training algorithm. It requires information from the gradient vector, and hence it is a first-order method.
梯度下降,也稱為最速下降,是最直接的訓練算法。 它需要來自梯度向量的信息,因此它是一階方法。
-----

Fig.
-----
The parameter η is the training rate. This value can either set to a fixed value or found by one-dimensional optimization along the training direction at each step. An optimal value for the training rate obtained by line minimization at each successive step is generally preferable. However, there are still many software tools that only use a fixed value for the training rate.
參數 η 是訓練率。 該值可以設置為固定值,也可以在每一步沿訓練方向通過一維優化找到。 通常優選在每個連續步驟通過線最小化獲得的訓練速率的最佳值。 但是,仍然有許多軟體工具僅將固定值用於訓練率。
The next picture is an activity diagram of the training process with gradient descent. As we can see, the parameter vector is improved in two steps: First, the gradient descent training direction is computed. Second, a suitable training rate is found.
下一張圖片是梯度下降訓練過程的活動圖。 可以看到,參數向量在兩個步驟中得到了改進:首先,計算梯度下降訓練方向。 第二,找到合適的訓練率。
-----

Fig.
-----
The gradient descent training algorithm has the severe drawback of requiring many iterations for functions which have long, narrow valley structures. Indeed, the downhill gradient is the direction in which the loss function decreases the most rapidly, but this does not necessarily produce the fastest convergence. The following picture illustrates this issue.
梯度下降訓練算法具有嚴重的缺點,即對於具有長而窄的谷底結構的函數,需要進行多次迭代。 確實,下坡是損失函數下降最快的方向,但這並不一定會產生最快的收斂。 下圖說明了此問題。
-----
----
References
[1] 5 algorithms to train a neural network
https://www.neuraldesigner.com/blog/5_algorithms_to_train_a_neural_network
[2] 從梯度下降到擬牛頓法:詳解訓練神經網絡的五大學習算法_機器之心 - 微文庫
https://www.luoow.com/dc_hk/108919053
[3] 從梯度下降到擬牛頓法:詳解訓練神經網絡的五大學習算法 - 每日頭條
https://kknews.cc/zh-tw/tech/p8nq8x8.html
-----
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.