2019/10/02
-----
Table of Contents
-----
1. Introduction
2. Prerequisites
3. Encoder — Decoder Architecture
4. Encoder LSTM
5. Decoder LSTM — Training mode
6. Decoder LSTM — Inference mode
7. Code Walk through
8. Results and Evaluation
9. Future Work
10. End Notes
11. References
-----
1. Introduction
-----
Recurrent Neural Networks (or more precisely LSTM/GRU) have been found to be very effective in solving complex sequence related problems given a large amount of data. They have real time applications in speech recognition, Natural Language Processing (NLP) problems, time series forecasting, etc. This blog nicely explains some of these applications.
-----
在給定大量數據的情況下,已經發現遞歸神經網絡(或更確切地說是LSTM / GRU)在解決複雜的序列相關問題方面非常有效。 他們在語音識別,自然語言處理(NLP)問題,時間序列預測等方面具有即時應用。此部落格很好地解釋了其中的一些應用。
-----
Sequence to Sequence (often abbreviated to seq2seq) models are a special class of Recurrent Neural Network architectures typically used (but not restricted) to solve complex Language related problems like Machine Translation, Question Answering, creating Chat-bots, Text Summarization, etc.
-----
序列到序列(通常縮寫為 seq2seq)模型是一類特殊的遞歸神經網路架構,通常用於(但不限於)解決與語言相關的複雜問題,例如機器翻譯,問答,創建聊天機器人,文本摘要等。
-----

Fig. 1. Complex language related problems.
-----
The purpose of this blog post is to give a detailed explanation on how sequence to sequence models are built and to give an intuitive understanding of how they solve these complex tasks.
-----
這篇部落格文章的目的是詳細解釋如何構建序列到序列模型,並直觀地了解它們如何解決這些複雜的任務。
-----
We will take the problem of Machine Translation (translating a text from one language to another, in our case from English to Marathi) as the running example in this blog. However the technical details apply to any sequence to sequence problem in general.
-----
在本部落格中,我們將以機器翻譯(將文本從一種語言翻譯為另一種語言,在本例中是從英語翻譯為馬拉地語)的問題為例。 但是,技術細節通常適用於任何序列到序列的問題。
-----
Since we are using Neural Networks to perform Machine Translation, more commonly it is called as Neural Machine translation (NMT).
-----
由於我們使用神經網路來執行機器翻譯,因此更普遍地稱為神經機器翻譯(NMT)。
-----
2. Prerequisites
-----
This post assumes that you:
a. Know Fundamental concepts in Machine Learning and Neural Networks
b. Know High School Linear Algebra and Probability
c. Have working knowledge of LSTM networks in Python and Keras
The Unreasonable Effectiveness of Recurrent Neural Networks (explains how RNNs can be used to build language models) and Understanding LSTM Networks (explains the working of LSTMs with solid intuition) are two brilliant blogs that I strongly suggest to go through if you haven’t. The concepts explained in these blogs are extensively used in my post.
-----
本文假設你:
a. 熟悉機器學習跟神經網路的基本觀念
b. 熟悉高中的線性代數與機率
c. 已經知道 LSTM 網路如何在 Python 與 Keras 中運作
循環神經網絡的不合理有效性(解釋瞭如何使用 RNN 構建語言模型)和理解 LSTM 網絡(以紮實的直覺解釋了LSTM 的工作)是兩個精采的部落格貼文,如果沒有,我強烈建議您進行研究。 這些部落格中解釋的概念在我的發文中得到了廣泛使用。
-----
3. Encoder — Decoder Architecture
-----
The most common architecture used to build Seq2Seq models is the Encoder Decoder architecture. This is the one we will use for this post. Below is a very high level view of this architecture.
-----
用於構建 Seq2Seq 模型的最常見的體系結構是編碼器解碼器架構。 這是我們將用於本文的內容。 下面是此架構的非常高階的視圖。
-----

Fig. 2. Encoder-Decoder structure.
-----
Points to note:
a. Both encoder and the decoder are typically LSTM models (or sometimes GRU models).
-----
注意事項:
a. 編碼器和解碼器通常都是 LSTM 模型(有時是 GRU 模型)。
-----
b. Encoder reads the input sequence and summarizes the information in something called as the internal state vectors (in case of LSTM these are called as the hidden state and cell state vectors). We discard the outputs of the encoder and only preserve the internal states.
-----
b. 編碼器讀取輸入序列並以稱為內部狀態向量的方式匯總信息(在 LSTM 的情況下,這些稱為隱藏狀態和單元狀態向量)。 我們丟棄編碼器的輸出,僅保留內部狀態。
-----
c. Decoder is an LSTM whose initial states are initialized to the final states of the Encoder LSTM. Using these initial states, decoder starts generating the output sequence.
-----
c. 解碼器是一種 LSTM,其初始狀態被初始化為編碼器 LSTM 的最終狀態。 使用這些初始狀態,解碼器開始生成輸出序列。
-----
d. The decoder behaves a bit differently during the training and inference procedure. During the training, we use a technique call teacher forcing which helps to train the decoder faster. During inference, the input to the decoder at each time step is the output from the previous time step.
-----
d. 解碼器在訓練和推理過程中的行為略有不同。 在訓練期間,我們使用一種稱為 teacher forcing 的技術,該技術有助於更快地訓練解碼器。 在推理期間,每個時間步長到解碼器的輸入是前一個時間點的輸出。
-----
e. Intuitively, the encoder summarizes the input sequence into state vectors (sometimes also called as Thought vectors), which are then fed to the decoder which starts generating the output sequence given the Thought vectors. The decoder is just a language model conditioned on the initial states.
-----
e. 直觀地,編碼器將輸入序列匯總為狀態向量(有時也稱為思想向量),然後將其饋送到解碼器,解碼器在給定思想向量的情況下開始生成輸出序列。 解碼器只是一種以初始狀態為條件的語言模型。
-----
Now we will understand all the above steps in detail by considering the example of translating an English sentence (input sequence) into its equivalent Marathi sentence (output sequence).
-----
現在,我們將通過考慮將英語句子(輸入序列)翻譯成等效的馬拉地語句子(輸出序列)的例子來詳細了解上述所有步驟。
-----
4. Encoder LSTM
-----
This section provides a brief overview of the main components of the Encoder LSTM. I will keep this intuitive without going into the Mathematical arena. So here’s what they are:
-----
本節簡單描述了編碼器 LSTM 的主要組件。 我將保持直觀,而不進入數學領域。 所以這就是它們:
-----

Fig. 3. LSTM processing an input sequence of length ‘k’
-----
The LSTM reads the data one sequence after the other. Thus if the input is a sequence of length ‘k’, we say that LSTM reads it in ‘k’ time steps (think of this as a for loop with ‘k’ iterations).
-----
LSTM 依次讀取數據。 因此,如果輸入是長度為“ k”的序列,那麼我們說 LSTM 會以“ k”次步驟讀取它(可以將其視為帶有“ k”個迭代的 for 迴圈)。
-----
Referring to the above diagram, below are the 3 main components of an LSTM:
a. Xi => Input sequence at time step i
b. hi and ci => LSTM maintains two states (‘h’ for hidden state and ‘c’ for cell state) at each time step. Combined together these are internal state of the LSTM at time step i.
c. Yi => Output sequence at time step i
-----
參考上圖,以下是 LSTM 的 3 個主要組件:
a. Xi => 輸入序列在時間點 i 處的值
b. hi 和 ci => LSTM 在每個時間點均維護兩個狀態(“ h”表示隱藏狀態,“ c”表示單元狀態)。 這些結合在一起就是時間步驟 i 處 LSTM 的內部狀態。
c. Yi => 輸出序列在時間點 i 處的值
-----
Important: Technically all of these components (Xi, hi, ci and Yi) are actually vectors of floating point numbers (explained below)
-----
重要提示:技術上而言,所有這些分量(Xi,hi,ci 和 Yi)實際上都是浮點數向量(如下所述)
-----
Let’s try to map all of these in the context of our problem. Recall that our problem is to translate an English sentence to its Marathi equivalent. For the purpose of this blog we will consider the below example. Say, we have the following sentence
Input sentence (English)=> “Rahul is a good boy”
Output sentence (Marathi) => “राहुल चांगला मुलगा आहे”
For now just focus on the input i.e. the English sentence
-----
讓我們嘗試根據我們的問題來對應所有這些。 回想一下,我們的問題是將英語句子翻譯成與 Marathi 等價的句子。 就本部落格而言,我們將考慮以下範例。 譬如,我們有以下句子
輸入句子(英語)=>“拉胡爾是個好男孩”
輸出語句(Marathi)=>“राहुलचांगलामुलगाआहे”
現在只關注輸入,即英語句子
-----
Explanation for Xi:
-----
Now a sentence can be seen as a sequence of either words or characters. For example in case of words, the above English sentence can be thought of as a sequence of 5 words (‘Rahul’, ‘is’, ‘a’, ‘good’, ‘boy’). And in case of characters, it can be thought of as a sequence of 19 characters (‘R’, ‘a’, ‘h’, ‘u’, ‘l’, ‘ ‘, ……, ‘y’).
-----
現在,一個句子可以看作是單字或字元的序列。 例如,在單詞的情況下,上述英語句子可以被認為是 5 個單字的序列(“ Rahul”,“ is”,“ a”,“ good”,“ boy”)。 對於字元,可以將其視為 19 個字元的序列(“ R”,“ a”,“ h”,“ u”,“ l”,“,……,y”)。
-----
We will break the sentence by words as this scheme is more common in real world applications. Hence the name ‘Word Level NMT’. So, referring to the diagram above, we have the following input:
X1 = ‘Rahul’, X2 = ‘is’, X3 = ‘a’, X4 = ‘good, X5 = ‘boy’.
The LSTM will read this sentence word by word in 5 time steps as follows
-----
我們將依照單字順序講解,因為這種方案在現實世界的應用中更為常見。 所以命名為“ Word Level NMT”。 因此,參考上圖,我們有以下輸入:
X1 = ‘Rahul’, X2 = ‘is’, X3 = ‘a’, X4 = ‘good, X5 = ‘boy’.
LSTM 將按以下 5 次時間點一一閱讀該句子
-----

Fig. 4. Encoder LSTM.
-----
But one question that we must answer is how to represent each Xi (each word) as a vector?
-----
但是,我們必須回答的一個問題是如何將每個 Xi(每個單字)表示為向量?
-----
There are various word embedding techniques which map (embed) a word into a fixed length vector. I will assume the reader to be familiar with the concept of word embeddings and won’t cover this topic in detail. However, we will use the built-in Embedding Layer of the Keras API to map each word into a fixed length vector.
-----
有多種詞嵌入技術可將詞映射(嵌入)成固定長度的向量。 我假定讀者熟悉單字嵌入的概念,所以不會詳細介紹此主題。 不過我們會使用 Keras API 的內置嵌入層將每個單字映射到固定長度的向量中。
-----
Explanation for hi and ci:
-----
The next question is what is the role of the internal states (hi and ci) at each time step?
-----
下一個問題是內部狀態(hi 和 ci)在每個時間點上的作用是什麼?
-----
In very simple terms, they remember what the LSTM has read (learned) till now. For example:
h3, c3 =>These two vectors will remember that the network has read “Rahul is a” till now. Basically its the summary of information till time step 3 which is stored in the vectors h3 and c3 (thus called the states at time step 3).
-----
簡單來說,他們記得 LSTM 到目前為止所讀(學習)的內容。 例如:
h3,c3 => 這兩個向量將記住,到目前為止,網路已讀取“ Rahul is a”。 基本上,它是直到時間點 3 的信息摘要,存儲在向量 h3 和 c3 中(因此稱為時間點 3 的狀態)。
-----
Similarly, we can thus say that h5, c5 will contain the summary of the entire input sentence, since this is where the sentence ends (at time step 5). These states coming out of the last time step are also called as the “Thought vectors” as they summarize the entire sequence in a vector form.
-----
類似地,我們可以說 h5,c5 將包含整個輸入句子的摘要,因為這是句子結尾的地方(在時間點 5)。 這些最後一步出現的狀態也稱為“思想向量”,因為它們以向量形式匯總了整個序列。
-----
Then what about h0,c0? These vectors are typically initialized to zero as the model has not yet started to read the input.
-----
那 h0,c0 呢? 由於模型尚未開始讀取輸入,因此通常將這些向量初始化為零。
-----
Note: The size of both of these vectors is equal to number of units (neurons) used in the LSTM cell.
-----
注意:這兩個向量的大小等於 LSTM 單元中使用的單位數(神經元)。
-----
Explanation for Yi:
-----
Finally, what about Yi at each time step? These are the output (predictions) of the LSTM model at each time step.
-----
最後,每個步驟的 Yi 怎麼辦? 這些是每個時間點 LSTM 模型的輸出(預測)。
-----
But what type of a vector is Yi? More specifically in case of word level language models each Yi is actually a probability distribution over the entire vocabulary which is generated by using a softmax activation. Thus each Yi is a vector of size “vocab_size” representing a probability distribution.
-----
但是 Yi 是什麼類型的向量? 更具體地說,在單字級語言模型的情況下,每個 Yi 實際上是通過使用 softmax 激活生成的整個詞彙表上的概率分佈。 因此,每個 Yi 是代表概率分佈的大小為“ vocab_size”的向量。
-----
Depending on the context of the problem they might sometimes be used or sometimes be discarded.
-----
根據問題的具體情況,有時可能會使用它們,有時會將它們丟棄。
-----
In our case we have nothing to output unless we have read the entire English sentence. Because we will start generating the output sequence (equivalent Marathi sentence) once we have read the entire English sentence. Thus we will discard the Yi of the Encoder for our problem.
-----
在我們的情況下,除非閱讀了整個英語句子,否則我們沒有任何輸出。 因為一旦我們閱讀了整個英語句子,我們將開始生成輸出序列(等效的馬拉地語句子)。 因此,對於我們的問題,我們將放棄編碼器的 Yi。
-----
Summary of the encoder:
-----
We will read the input sequence (English sentence) word by word and preserve the internal states of the LSTM network generated after the last time step hk, ck (assuming the sentence has ‘k’ words). These vectors (states hk and ck) are called as the encoding of the input sequence, as they encode (summarize) the entire input in a vector form. Since we will start generating the output once we have read the entire sequence, outputs (Yi) of the Encoder at each time step are discarded.
-----
我們將逐字讀取輸入序列(英語句子),並保留在最後一個時間點 hk,ck(假設句子中有“ k”個詞)之後生成的 LSTM 網路的內部狀態。 這些向量(狀態 hk 和 ck)被稱為輸入序列的編碼,因為它們以向量形式對整個輸入進行編碼(匯總)。 由於一旦讀取了整個序列就將開始生成輸出,因此將丟棄每個時間點的編碼器的輸出(Yi)。
-----
Moreover you must also understand what type of vectors are Xi, hi, ci and Yi. What are their sizes (shapes) and what do they represent. If you have any confusion understanding this part, then you need to first strengthen your understanding of LSTM and language models.
-----
此外,您還必須了解什麼類型的向量是 Xi,hi,ci 和 Yi。 它們的大小(形狀)是什麼,它們代表什麼。 如果您對這部分有任何困惑,則需要首先加深對 LSTM 和語言模型的理解。
-----
5. Decoder LSTM — Training Mode
-----
Unlike the Encoder LSTM which has the same role to play in both the training phase as well as in the inference phase, the Decoder LSTM has a slightly different role to play in both of these phases.
-----
與在訓練階段和推理階段中扮演相同角色的編碼器 LSTM 不同,在這兩個階段中,解碼器 LSTM 扮演的角色略有不同。
-----
In this section we’ll try to understand how to configure the Decoder during the training phase, while in the next section we’ll understand how to use it during inference.
-----
在本節中,我們將嘗試了解如何在訓練階段配置解碼器,而在下一節中,我們將了解在推理期間如何使用解碼器。
-----
Recall that given the input sentence “Rahul is a good boy”, the goal of the training process is to train (teach) the decoder to output “राहुल चांगला मुलगा आहे”. Just as the Encoder scanned the input sequence word by word, similarly the Decoder will generate the output sequence word by word.
-----
回想一下,給定輸入語句“Rahul is a good boy”,訓練過程的目標是訓練(教)解碼器以輸出“राहुलचांगलांगलाआहे”。 就像編碼器逐字掃描輸入序列一樣,解碼器也將逐字生成輸出序列。
-----
For some technical reasons (explained later) we will add two tokens in the output sequence as follows:
Output sequence => “START_ राहुल चांगला मुलगा आहे _END”
Now consider the diagram below:
-----
出於某些技術原因(稍後說明),我們將在輸出序列中添加兩個代號,如下所示:
輸出序列=>“START_ राहुल चांगला मुलगा आहे _END”
現在考慮下圖:
-----

Fig. 5. Decoder LSTM — Training Mode.
-----
The most important point is that the initial states (h0, c0) of the decoder are set to the final states of the encoder. This intuitively means that the decoder is trained to start generating the output sequence depending on the information encoded by the encoder. Obviously the translated Marathi sentence must depend on the given English sentence.
-----
最重要的一點是,解碼器的初始狀態(h0,c0)設置為編碼器的最終狀態。 從直覺上講,這意味著對解碼器進行培訓,以根據編碼器編碼的信息開始生成輸出序列。 顯然,翻譯後的馬拉地語句子必須取決於給定的英語句子。
-----
在第一步中,我們提供 START_代號,以便解碼器開始生成下一個代號(Marathi 句子的實際第一個單字)。 在Marathi 句子中的最後一個單字之後,我們使解碼器學習預測 _END 代號。 這將用作推理過程中的停止條件,基本上它將表示翻譯後的句子的結尾,並且我們將停止推理循環(稍後將對此進行詳細介紹)。
-----
We use a technique called “Teacher Forcing” wherein the input at each time step is given as the actual output (and not the predicted output) from the previous time step. This helps in more faster and efficient training of the network. To understand more about teacher forcing, refer this blog.
-----
我們使用一種稱為 “Teacher Forcing”的技術,其中每個時間步長的輸入均作為上一個時間步長的實際輸出(而不是預測輸出)給出。 這有助於更快更有效地訓練網路。 要了解有關 “Teacher Forcing”的更多信息,請參閱此部落格。
https://machinelearningmastery.com/teacher-forcing-for-recurrent-neural-networks/
-----
Finally the loss is calculated on the predicted outputs from each time step and the errors are back propagated through time in order to update the parameters of the network. Training the network over longer period with sufficiently large amount of data results in pretty good predictions (translations) as we’ll see later.
-----
最終,根據每個時間步長的預測輸出計算誤差,並通過時間將誤差反向傳播,以更新網路的參數。 我們會在以後看到,使用足夠大量的數據對網路進行長時間的訓練會產生很好的預測(翻譯)。
-----
The entire training process (Encoder + Decoder) can be summarized in the below diagram:
-----
下圖總結了整個訓練過程(編碼器+解碼器):
-----

Fig. 6. Summary of the training process.
-----
6. Decoder LSTM — Inference Mode
-----
Let’s now try to understand the setup required for inference. As already stated the Encoder LSTM plays the same role of reading the input sequence (English sentence) and generating the thought vectors (hk, ck).
-----
現在,讓我們嘗試了解推理所需的設置。 如前所述,編碼器 LSTM 在讀取輸入序列(英語句子)和生成 thought vectors(hk,ck)方面起著相同的作用。
-----
However, the decoder now has to predict the entire output sequence (Marathi sentence) given these thought vectors.
-----
但是,基於這些 thought vectors,解碼器現在必須預測整個輸出序列(馬拉地語句子)。
-----
Let’s try to visually understand by taking the same example.
Input sequence => “Rahul is a good boy”
(Expected) Output Sequence => “राहुल चांगला मुलगा आहे”
-----
讓我們嘗試通過相同的例子來直觀地了解。
輸入序列 =>“Rahul is a good boy”
(預期的)輸出順序=>“राहुलचांगलामुलगाआहे”
-----
Step 1: Encode the input sequence into the Thought Vectors:
-----
步驟1:將輸入序列編碼為 Thought Vectors:
-----

Fig. 7. Encode the input sequence into thought vectors.
-----
Step 2: Start generating the output sequence in a loop, word by word:
-----
步驟2:開始逐個單字地循環生成輸出序列:
-----
Att = 1
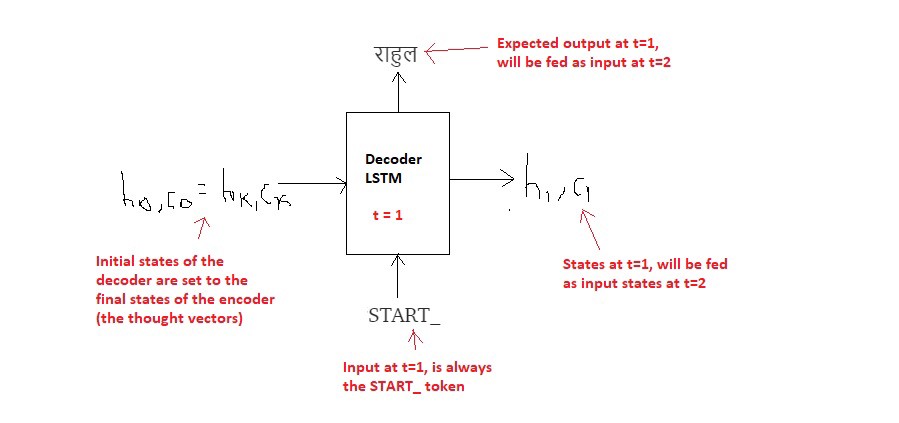
Fig. 8. Decoder at t = 1.
-----
Att = 2

Fig. 9. Decoder at t = 2.
-----
Att = 3

Fig. 10. Decoder at t = 3.
-----
Att = 4

Fig. 11. Decoder at t = 4.
-----
Att = 5

Fig. 12. Decoder at t = 5.
-----
Inference Algorithm:
-----
a. During inference, we generate one word at a time. Thus the Decoder LSTM is called in a loop, every time processing only one time step.
-----
a. 在推論過程中,我們一次生成一個單字。 因此,在迴圈中,重複呼叫 Decoder LSTM,每次僅處理一個時間點。
-----
b. The initial states of the decoder are set to the final states of the encoder.
-----
b. 解碼器的初始狀態設置為編碼器的最終狀態。
-----
c. The initial input to the decoder is always the START_ token.
-----
c. 解碼器的初始輸入始終是 START_ token。
-----
d. At each time step, we preserve the states of the decoder and set them as initial states for the next time step.
-----
d. 在每個時間點,我們都保留解碼器的狀態,並將其設置為下一時間點的初始狀態。
-----
e. At each time step, the predicted output is fed as input in the next time step.
-----
e. 在每個時間點,預測的輸出將作為下一個時間點的輸入。
-----
f. We break the loop when the decoder predicts the END_ token.
-----
f. 當解碼器預測 END_ token 時,我們結束迴圈。
-----
The entire inference procedure can be summarized in the below diagram:
-----
下圖總結了整個推理過程:
-----

Fig. 12. Summary of the inference process.
-----
7. Code Walk through
-----
Nothing beats the understanding developed when we actually implement the code, no matter how much efforts are put in to understand the theory (that does not however mean that we do not discuss any theory, but what I mean to say is theory must always be followed by implementation).
-----
無論我們有多努力來理解該理論,都不會超越我們實際執行代碼時所形成的理解(但是,這不代表我們不討論任何理論,我的意思是說,理論之後要動手實作)。
-----
Dataset:
-----
Download and unzip mar-eng.zip file from here.
-----
從此處下載mar-eng.zip文件並解壓縮。
http://www.manythings.org/anki/
-----
Before we start building the models, we need to perform some data cleaning and preparation. Without going into too much details, I will assume the reader to understand the below (self explanatory) steps that are usually a part of any language processing project.
-----
在開始構建模型之前,我們需要執行一些數據清理和準備工作。 在不贅述的前提下,我將假定讀者理解以下(自我說明)的步驟,這些步驟通常是任何語言處理項目的一部分。
-----
Code to perform Data Cleaning(參考原文章)
-----
Below we compute the vocabulary for both English and Marathi. We also compute the vocabulary sizes and the length of maximum sequence for both the languages. Finally we create 4 Python dictionaries (two for each language) to convert a given token into an integer index and vice-versa.
-----
下面我們計算英語和馬拉地語的詞彙量。 我們還計算兩種語言的詞彙量和最大序列的長度。 最後,我們創建 4 個 Python 字典(每種語言兩個),將給定的 token 轉換為整數索引,反之亦然。
-----
Code for Data Preparation(參考原文章)
-----
Then we make a 90–10 train and test split and write a Python generator function to load the data in batches as follows:
-----
然後,我們進行了 90-10 次訓練和測試拆分,並編寫了 Python 生成器函數來分批加載數據,如下所示:
-----
Code for loading Batches of Data(參考原文章)
-----
Then we define the model required for training as follows:
-----
然後,我們定義訓練所需的模型,如下所示:
-----
Code to define the Model to be trained
-----
You should be able to conceptually connect each and every line with the explanation I have provided in sections 4 and 5 above.
-----
你應該能夠在概念上將每一行與我在上面的第 4 部分和第 5 部分中提供的解釋聯繫起來。
-----
Let’s look at the model architecture generated from the plot_model utility of the Keras.
-----
讓我們看一下從 Keras 的 plot_model 實用程序生成的模型架構。
-----

Fig. 13. Training the network.
-----
We train the network for 50 epochs with a batch size of 128. On a P4000 GPU, it takes slightly more than 2 hours to train.
-----
我們以 50 個 epochs 訓練網路,批量大小為 128。在 P4000 GPU 上,訓練需要略超過 2 個小時。
-----
Inference Setup:
-----
Code for setting up Inference(參考原文章)
-----
Finally, we generate the output sequence by invoking the above setup in a loop as follows:
-----
最後,我們通過循環調用上述設置來生成輸出序列,如下所示:
-----
Code to decode the output sequence in a loop(參考原文章)
-----
At this point you must be able to conceptually connect each and every line of the code in the above two blocks with the explanation provided in section 6.
-----
此時,你必須能夠在概念上將以上兩個模塊中的每一行代碼與第 6 節中提供的說明進行連接。
-----
8. Results and Evaluation
-----
The purpose of this blog post was to give an intuitive explanation on how to build basic level sequence to sequence models using LSTM and not to develop a top quality language translator. So keep in mind that the results are not world class (and you don’t start comparing with google translate) for many reasons. The most important reason being is that the dataset size is very small, only 33000 pairs of sentences (yes these are too few). If you want to improve the quality of translations, I will list some suggestions towards the end of this blog. However for now, let’s see some results generated from the above model (they are not too bad either).
-----
這篇博文的目的是對如何使用 LSTM 構建基本水平序列以建立序列模型提供直觀的解釋,而不是開發高水準的語言翻譯器。 因此請記住,由於多種原因,結果並不是世界一流的(並且您不會開始與 Google 翻譯進行比較)。 最重要的原因是數據集很小,只有 33000 對句子(是的,這太少了)。 如果您想提高翻譯質量,我將在本博客結尾處列出一些建議。 但是,現在,讓我們看看以上模型產生的一些結果(它們也不錯)。
-----
Evaluation on train dataset:
-----
Evaluation on Training Dataset(參考原文章)
-----
Evaluation on test dataset:
-----
Evaluation on Test Dataset(參考原文章)
-----
What can we conclude?
-----
Even though the results are not the best, they are not that bad as well. Certainly much better than what a randomly generated sequence would result in. In some sentences we can even note that the words predicted are not correct but they are semantically quite close to the correct words.
-----
即使結果不是最好的,也不是那麼糟糕。 當然,它比隨機生成的序列所產生的結果要好得多。在某些句子中,我們甚至可以注意到預測的單字不是正確的,但從語義上講它們與正確的單字非常接近。
-----
Also, another point to be noticed is that the results on training set are a bit better than the results on test set, which indicates that the model might be over-fitting a bit.
-----
另外,要注意的另一點是,訓練集上的結果比測試集上的結果好一點,這表明模型可能有點過擬合。
-----
9. Future Work
-----
If you are interested to improve the quality, you can try out below measures:
-----
如果您有興趣提高品質,可以嘗試以下措施:
-----
a. Get much more data. Top quality translators are trained on millions of sentence pairs.
-----
a. 獲取更多數據。 高水準的翻譯機,其訓練集包含數百萬個句子對。
-----
b. Build more complex models like Attention.
-----
b. 建立像 Attention 這樣更複雜的模型。
-----
c. Use dropout and other forms of regularization techniques to mitigate over-fitting.
-----
c. 使用 dropout 和其他形式的正則化技巧來降低過度擬合。
-----
d. Perform Hyper-parameter tuning. Play with learning rate, batch size, dropout rate, etc. Try using bidirectional Encoder LSTM. Try using multi-layered LSTMs.
-----
d. 執行超參數調整。 以學習率,批處理大小,dropout rate 等進行調整。嘗試使用雙向編碼器 LSTM。 嘗試使用多層 LSTM。
-----
e. Try using beam search instead of a greedy approach.
-----
e. 嘗試使用 beam search 而不是 greedy approach。
-----
f. Try BLEU score to evaluate your model.
-----
f. 嘗試使用 BLEU 評分來評估你的模型。
-----
g. The list is never ending and goes on.
-----
g. 列表永無止境,而且還在繼續。
-----
10. End Notes
-----
If the article appeals you, do provide some comments, feedback, constructive criticism, etc.
-----
如果文章吸引您,請提供一些評論,反饋,建設性的批評等。
-----
Full code on my GitHub repo here.
-----
完整代碼在我的 GitHub 存儲庫中。
https://github.com/hlamba28/Word-Level-Eng-Mar-NMT
-----
If you like my explanations, you can follow me as I plan to release some more interesting blogs related to Deep Learning and AI.
-----
如果您喜歡我的解釋,可以追蹤我,因為我準備繼續發表一些與深度學習和 AI 有關的更有趣的博文。
-----
You can connect on LinkedIn here
-----
您可以在 LinkedIn 上跟我取得聯繫!
https://www.linkedin.com/in/harshall-lamba-55a14a4b/
-----
11. References
-----
(參考原文章)
-----
References
# 793 claps。更新 1.6k claps。
Word Level English to Marathi Neural Machine Translation using Encoder-Decoder Model
https://towardsdatascience.com/word-level-english-to-marathi-neural-machine-translation-using-seq2seq-encoder-decoder-lstm-model-1a913f2dc4a7
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.