2017/04/06
前言:
資料很多,先理出個頭緒以便按圖索驥。
-----
Summary:
Deep learning (DL) [1]-[40] + reinforcement l earning (RL) [41]-[44] = Deep reinforcement learning (DRL) [45]-[53]。
這四個多月以來,我利用下班時間自學一點 DL [1]-[20]。嚴格說來,不能算是完全自學,因為社團內的先進很熱心,陸陸續續受到 Jason、Winston 等先進的指導,所以還算蠻順利的。最近因為 Jason 除了原來 DL 的讀書會之外 [29],新增了 RL 的讀書會 [41],而我也獲得新的 DRL 資訊 [20],所以藉這個機會,重新擬定一下自己的讀書計畫,參考圖1.1。
一開始,我查了一些回顧性質的論文 [1],隨著 S/W tools 的貼文 [2],引來一連串的討論 [3]-[8],而我也開始從 BP [9]、AD [10]、LeNet [12], [13]、CNN [18]、RNN [19] 一路看下來。與此同時,我還是不斷地問自己,DL 是什麼 [1], [11], [17], [20]?
整理完 DRL 的參考資料,大約可說稍有概念了!

Fig. 1.1. Deep reinforcement learning.
-----
Introduction
AI 要如何定義,圖1.2告訴我們,由淺入深是 ML、RL、DL。圖1.3則是把相關技術分為 Deep、Shallow,Supervised、Unsupervised。圖 1.4則是舉出另外還有 Reinforcement Learning。結合 DL 與 RL,目前 DRL 是一重要的發展方向。
到目前為止,我大概可以對 DL 下個不算精確的定義隨時提醒自己:DL 為一連續可微的函數表現為多層的網路,其輸入與輸出均為向量。每層前半為線性,後半段為非線性。f(x, w, b) = y,訓練的目的在於找出 w、b 值使得所有 x 輸入的誤差很小。其方法是 BP,對某個 x 輸入固定時,w、b 為變數,沿著讓 cost function 的偏導數變小的方向調整 w、b,則可讓誤差函數慢慢收斂。
以上這段是寫給自己的,不懂的人看不懂,懂得的人不用看。
以下共分六部分,A、B、C 為基礎到進階的 DL。D 為 RL,E、F 為 DRL,參考圖1.1,數字為我幫自己設計的課程順序。本文主要以解釋順序為主。

Fig. 1.2. AI, p. 9 [29].

Fig. 1.3. Deep learning taxonomy, p. 492 [28].

Fig. 1.4. Machine learning, p. 515 [28].
-----
A, 01-07
Part A 屬於 DL 的基礎部分,有關這個,我特別想推薦 [28],這本書有電子版可以下載。它寫的不算很好,有的地方太簡略。但好處是 DL 就一章,RL 也一章,你不用在一開始就去啃 [29],即使我現在對於CNN [18] 與 RNN [19] 已經有一點瞭解,[29] 的相關章節我還是認為不容易閱讀。
論文的部分,[23] 是可以先看一下的,因為它主要是介紹性質。[21] 裡面有好幾種基本架構簡介,也是可以反覆閱讀的。這樣先熱身一下,接下來就可以專攻 LeNet 了 [12]。
-----
B, 08-10
RNN 是可以記憶的單元,加上 Controller,則有 Neural Turing Machine (NTM)、Differential Neural Computer (DNC ) 與 Memory Augmented Neural Network (MANN) 的架構 [30]-[37]。
-----
C, 11-15
這個部分主要是生成模型。
圖 2.1a 指出,Autoencoders (AE) 之後是 RL。看 Deep Generative Models (DGM) 之前也得先看 AE。
Boltzmann Machine 在二十章前半部,VAE 與 GAN 都藏身在 20.10 裡,參考圖2.2a。

Fig. 2.1a. Deep Learning, p. 12 [29].

Fig. 2.1b. Autoencoder, p. 501 [28].

Fig. 2.1c. Representation learning, [38].

Fig. 2.2a. Deep generative models, [29].

Fig. 2.2b. Restricted Boltzmann machine, p. 498 [28].
-----
D, 16-23
有關 Representation Learning,[41] 這本不容易啃,所以我從 [28] 裡面先把重點找出來,首先是四個比較重要的技術,分別是 Dynamic Programming (DP)、Monte Carlo Methods (MCM)、 Temporal Difference (TD) Learning、以及 Policy Gradient Method (PGM)。
MCM 很重要,[29] 裡也有一章。TD 可能是最重要的,參考圖3.2a。所以我也找了 Q-Learning 的資料 [43], [44]。
從圖3.1a中,我們知道,Markov Decision Process (MDP) 跟 Functional Approximation (FA) 是基礎。FA 在 [41] 裡面有不少章,但是想看懂 AlphaGo [50] 的話,少不了 FA,所以整本 [41] 還是跑不掉的。
MDP,簡單來說就是sars,參考圖3.1b。

Fig. 3.1a. RL basis, p. 513 [28].
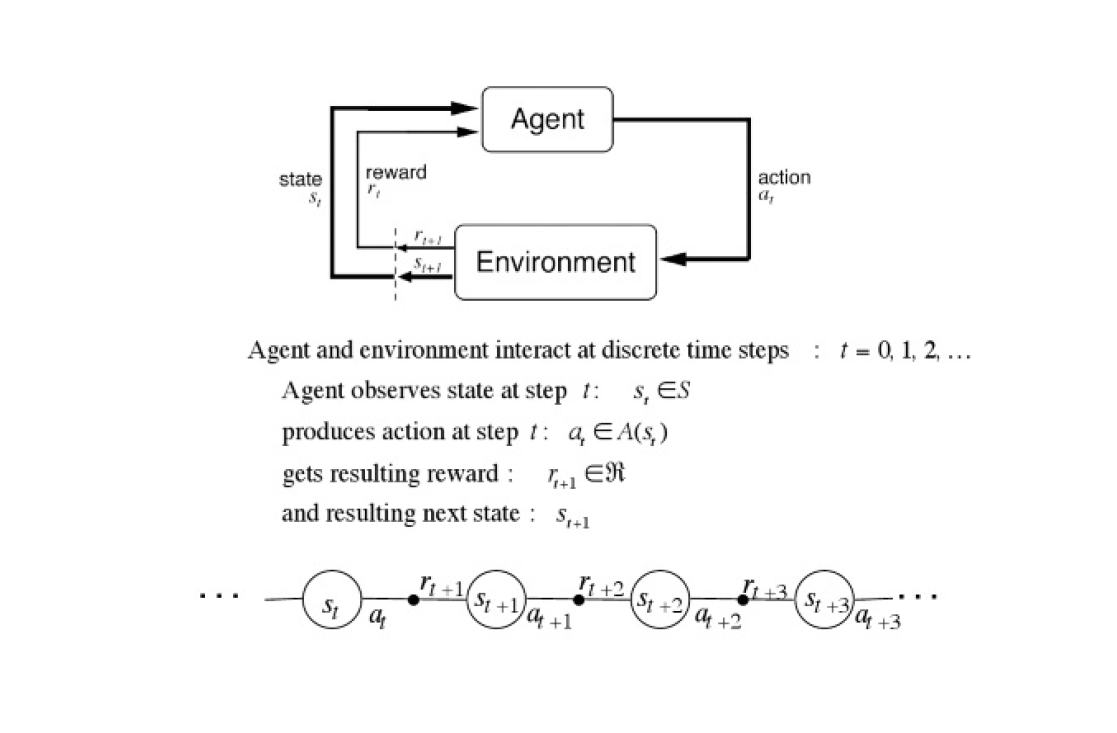
Fig. 3.1b. Basic RL model, p. 524 [28].

Fig. 3.2a. RL methods, p. 513 [28].

Fig. 3.2b. Q-learning, p. 537 [28].

Fig. 3.2c. Actor-Critic, p. 538 [28].
-----
E, 24-27
[45] 有很詳細的 DRL 介紹,包含今年 2017 的出版論文。ATARI 電玩是 DQN、S3C、UNREAL 這幾篇論文的重點 [46]-[49]。
-----
F, 28-34
最後是 AlphaGo [50],這個有好幾篇中文文章介紹它用的技術 [11],除了 CNN 之外,還用到 PGM [51] 以及 MCTS [52], [53]。由於這個 PGM 有用到 function approximation,所以要把 [41] 讀完,才能真正瞭解 AlphaGo。
-----
結論:
很快把 DRL 整個帶過一遍。算是地圖而非旅遊指南。後面還有很長的路要走呢!
-----

Fig. 4.1a. Policy gradient method [50].

Fig. 4.1b. Policy and value networks [50].

Fig. 4.1c. Monte Carlo tree search (MCTS) [50].

Fig. 4.2. Actor-critic artificial neural network and a hypothetical neural implementation, p. 340 [41].
-----
References
[1] AI從頭學(一):文獻回顧
[2] AI從頭學(二):Popular Deep Learning Software Tools
[3] AI從頭學(三):Popular Deep Learning Hardware Tools
[4] AI從頭學(四):AD and LeNet
[5] AI從頭學(五):AD and Python
[6] AI從頭學(六):The Net
[7] AI從頭學(七):AD and Python from Jason
[8] AI從頭學(八):The Net from Mark
[9] AI從頭學(九):Back Propagation
[10] AI從頭學(一0):Automatic Differentiation
[11] AI從頭學(一一):A Glance at Deep Learning
[12] AI從頭學(一二):LeNet
[13] AI從頭學(一三):LeNet - F6
[14] AI從頭學(一四):Recommender
[15] AI從頭學(一五):Deep Learning,How?
[16] AI從頭學(一六):Deep Learning,What?
[17] AI從頭學(一七):Shallow Learning
[18] AI從頭學(一八):Convolutional Neural Network
[19] AI從頭學(一九):Recurrent Neural Network
[20] AI從頭學(二0):Deep Learning,Hot
[21] Wang, Hao, and Dit-Yan Yeung. "Towards Bayesian Deep Learning: A Survey." arXiv preprint arXiv:1604.01662 (2016).
[22] Lacey, Griffin, Graham W. Taylor, and Shawki Areibi. "Deep learning on fpgas: Past, present, and future." arXiv preprint arXiv:1602.04283 (2016).
[23] LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." Nature 521.7553 (2015): 436-444.
[24]Schmidhuber, Jürgen. "Deep learning in neural networks: An overview." Neural networks 61 (2015): 85-117.
[25]Deng, Li, and Dong Yu. "Deep learning: methods and applications." Foundations and Trends® in Signal Processing 7.3–4 (2014): 197-387.
[26] Bengio, Yoshua, Aaron C. Courville, and Pascal Vincent. "Unsupervised feature learning and deep learning: A review and new perspectives." CoRR, abs/1206.5538 1 (2012).
[27] Bengio, Yoshua. "Learning deep architectures for AI." Foundations and trends® in Machine Learning 2.1 (2009): 1-127.
[28] Gollapudi, Sunila . Practical machine learning. Packt Publishing, 2016.
[29] Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. Deep learning. MIT Press, 2016.
http://www.deeplearningbook.org/
[30]
[31] 程式編寫程式:泛用人工智慧領域的一顆明珠 - 歌穀穀
http://www.gegugu.com/2017/03/16/9050.html
[32] 深度學習挑戰馮·諾依曼結構_幫趣網
bangqu.com/gpu/blog/5239
[33] 深度學習的新方向 One-shot learning - George's Research Website
http://tzuching1.weebly.com/blog/-one-shot-learning
[34] Olah, Chris, and Shan Carter. "Attention and Augmented Recurrent Neural Networks." Distill 1.9 (2016): e1.
http://distill.pub/2016/augmented-rnns/
[35] Graves, Alex, Greg Wayne, and Ivo Danihelka. "Neural turing machines." arXiv preprint arXiv:1410.5401 (2014).
[36] Graves, Alex, et al. "Hybrid computing using a neural network with dynamic external memory." Nature 538.7626 (2016): 471-476.
[37] Santoro, Adam, et al. "One-shot learning with memory-augmented neural networks." arXiv preprint arXiv:1605.06065 (2016).
[38] Bengio, Yoshua, Aaron Courville, and Pascal Vincent. "Representation learning: A review and new perspectives." IEEE transactions on pattern analysis and machine intelligence 35.8 (2013): 1798-1828.
[39] Doersch, Carl. "Tutorial on variational autoencoders." arXiv preprint arXiv:1606.05908 (2016).
[40] Goodfellow, Ian, et al. "Generative adversarial nets." Advances in neural information processing systems. 2014.
[41] Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. (2016): 424.
http://incompleteideas.net/sutton/book/bookdraft2016sep.pdf
[42] Heidrich-Meisner, Verena, et al. "Reinforcement learning in a nutshell." ESANN. 2007.
[43] Watkins, Christopher JCH, and Peter Dayan. "Q-learning." Machine learning 8.3-4 (1992): 279-292.
[44] Artificial Intelligence - foundations of computational agents -- 11_3_3 Q-learning
http://artint.info/html/ArtInt_265.html
[45] Li, Yuxi. "Deep reinforcement learning: An overview." arXiv preprint arXiv:1701.07274 (2017).
[46] 深度增強學習前沿算法思想 - 歌穀穀
http://www.gegugu.com/2017/02/17/1360.html
[47] Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533.
[48] Mnih, Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." International Conference on Machine Learning. 2016.
[49] Jaderberg, Max, et al. "Reinforcement learning with unsupervised auxiliary tasks." arXiv preprint arXiv:1611.05397 (2016).
[50] Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
[51] Sutton, Richard S., et al. "Policy gradient methods for reinforcement learning with function approximation." NIPS. Vol. 99. 1999.
[52] Browne, Cameron B., et al. "A survey of monte carlo tree search methods." IEEE Transactions on Computational Intelligence and AI in games 4.1 (2012): 1-43.
[53] Huang, Shih-Chieh, and Martin Müller. "Investigating the limits of Monte-Carlo tree search methods in computer Go." International Conference on Computers and Games. Springer International Publishing, 2013.